AI Agent
Le node AI Agent exécute un LLM autonome capable de planifier, d'appeler des outils, d'interroger des bases de connaissances et d'utiliser des serveurs MCP pour accomplir des tâches multi-étapes.
À quoi sert le node AI Agent ?
Le node AI Agent transforme un LLM en exécuteur autonome. Contrairement au node LLM — qui produit une réponse unique à partir d’un prompt — l’Agent raisonne sur vos instructions, décide quels outils, datasources ou serveurs MCP appeler, observe les résultats et itère jusqu’à atteindre l’objectif. Il renvoie une seule réponse texte une fois qu’il considère la tâche terminée.
Cas d’usage typiques :
- Recherche multi-étapes combinant recherche web, scraping et synthèse dans un seul node.
- Question-réponse ancrée sur une base de connaissances privée via RAG (datasources).
- Pilotage de systèmes externes via des serveurs MCP (API internes, bases de données) sans avoir à créer de nodes dédiés.
- Workflows d’enrichissement de données mêlant contexte documentaire, outils web et raisonnement structuré.
Configuration rapide
Suivez ces étapes pour ajouter et configurer le node AI Agent dans votre workflow :
Ajouter le node au canevas
Ouvrez la bibliothèque de nodes (Node Library), allez dans la catégorie AI et glissez-déposez le node Agent sur votre espace de travail.
Choisir un modèle
Dans les paramètres, sélectionnez un LLM dans le menu Model name. Les modèles avec capacités de raisonnement (classe GPT-4, Claude Sonnet/Opus, Gemini Pro) sont fortement recommandés — les modèles plus faibles bouclent ou utilisent mal les outils.
Rédiger les instructions
Dans le champ prompt, décrivez l’objectif, les étapes attendues, les contraintes et le format de sortie. Utilisez la syntaxe {{variable}} pour injecter des valeurs depuis les nodes amont.
Attacher les capacités
Ajoutez la combinaison souhaitée de Tools (outils intégrés de l’agent), de datasources RAG et de MCP Servers. L’agent décide à l’exécution quand utiliser chacun.
Connecter la sortie
Reliez le point de sortie au node suivant et définissez le nom de la variable de réception dans ce node pour exploiter la réponse finale de l’agent.
Paramètres de configuration
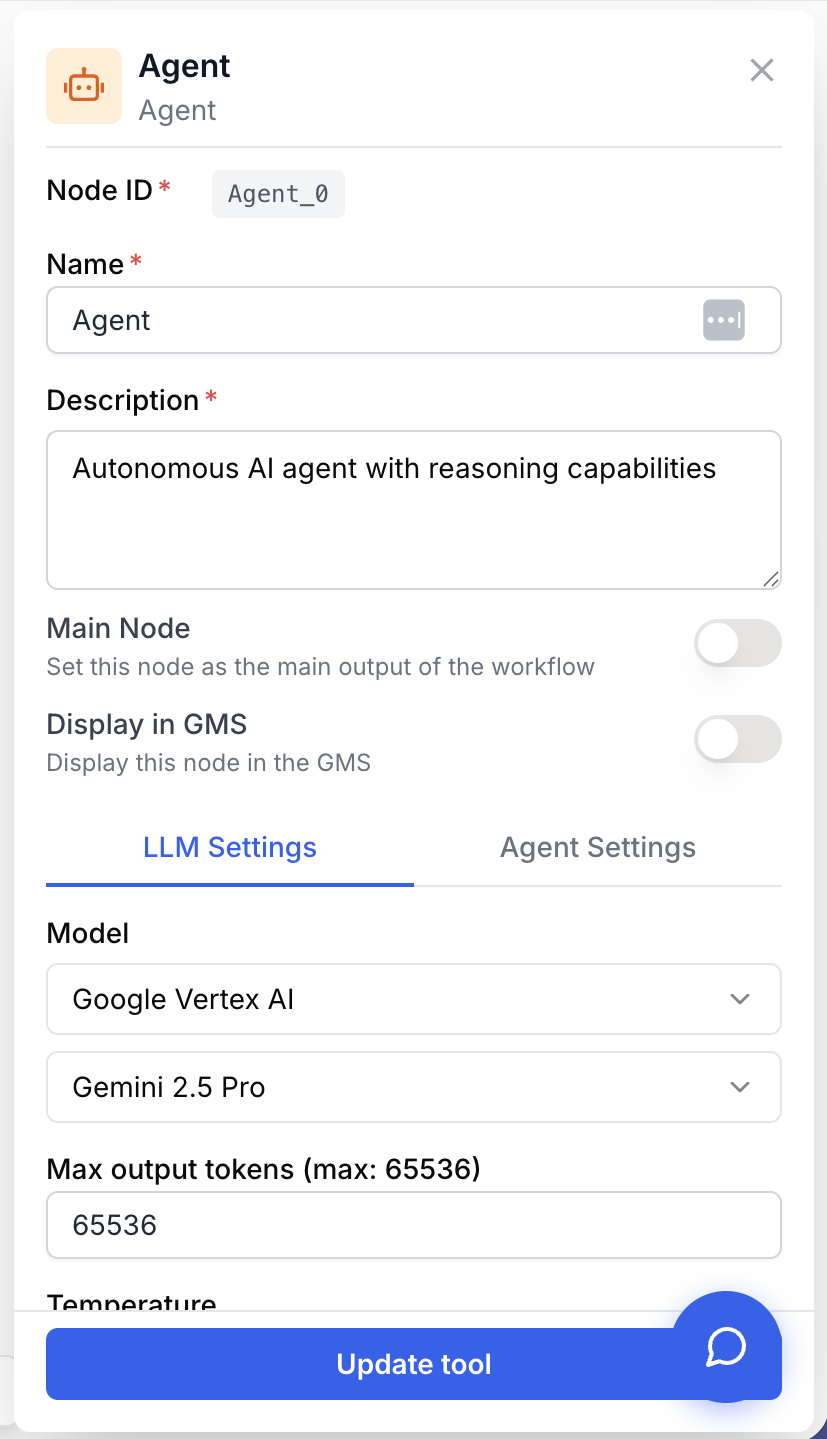
Configurer le node revient à choisir un modèle, rédiger des instructions claires et exposer les bonnes capacités — rien d’autre n’est obligatoire.
Champs requis
Name string required default: Agent Nom du node — Sert à identifier le node lors de l’exécution et du débogage du workflow (ex : “Agent enrichissement leads”).
Description string required default: A tool for interacting with a Large Language Model in Agent mode. Description du node — Courte phrase décrivant le rôle de cet agent dans votre workflow.
Model name llm required LLM qui pilote l’agent — Sélectionne le modèle et son provider. L’agent hérite du plafond Max output tokens du provider. Les modèles avec capacités de raisonnement sont nettement plus efficaces en mode agent.
prompt string required Instructions — La tâche et l’objectif que l’agent doit accomplir. Supporte les variables dynamiques {{myVariable}} (caractères autorisés : -, _, .). Le node échoue à la validation de configuration si ce champ est vide.
Champs optionnels
System Message string agentSystemMessage — Instructions de niveau système qui définissent le persona, le rôle et les règles globales de l’agent. Appliquées avant le prompt utilisateur à chaque étape de la boucle.
Tools array default: [] agentTools — Outils intégrés que l’agent peut appeler (recherche web, scraping, helpers internes). L’agent décide quand et combien de fois invoquer chacun.
RAG array default: [] agentDatasources — Bases de connaissances ou collections de documents que l’agent peut interroger pour produire des réponses ancrées. Utile pour le question-réponse sur votre propre contenu.
MCP Servers array default: [] agentMcpServers — Serveurs MCP avec lesquels l’agent peut dialoguer. Chaque serveur expose sa propre boîte à outils, ce qui permet de brancher des intégrations personnalisées sans construire de nodes dédiés.
Temperature number default: 1 Température d’échantillonnage. Des valeurs basses (0,2–0,5) rendent la sélection d’outils et le raisonnement plus déterministes ; des valeurs hautes augmentent la variabilité.
Max output tokens number default: 4000 Limite supérieure de tokens pour la réponse finale. Minimum 4000. À augmenter si les réponses de l’agent sont coupées.
Top K number default: 40 Restreint l’échantillonnage aux K tokens les plus probables à chaque étape.
Top P number default: 1.0 Nucleus sampling : conserve le plus petit ensemble de tokens dont la probabilité cumulée est ≥ P. Plage 0–1.
Thinking Level string Niveau d’effort pour les modèles de raisonnement exposant un contrôle de thinking (ex : low, medium, high). Laissez vide pour les modèles qui ne le supportent pas.
Thinking Budget number Nombre maximal de tokens que le modèle peut consommer dans sa phase de thinking, pour les modèles qui exposent un budget.
LLM Provider string Auto-rempli depuis le modèle sélectionné. Identifie le routage du provider (OpenAI, Anthropic, Google, etc.).
Combinez System Message + prompt : placez le rôle et les règles stables dans le system message, et la tâche par exécution (avec {{variables}}) dans le prompt. Vous obtenez un comportement cohérent entre runs sans réécrire tout le bloc d’instructions.
Que renvoie le node ?
Le node renvoie la réponse texte finale de l’agent sous forme de string — une fois qu’il décide que la tâche est terminée. Les appels d’outils, le raisonnement intermédiaire et les observations ne font pas partie de la sortie : seule la réponse l’est.
Comment récupérer l’output ?
Dans Draft & Goal, vous n’avez pas besoin de chercher un nom de variable complexe généré par le système. Pour exploiter le résultat :
- Tirez un lien depuis la sortie du node AI Agent.
- Connectez-le à l’entrée du node suivant.
- Dans ce node suivant, créez et nommez votre propre variable (par exemple
agent_answer). La réponse finale de l’agent y sera injectée automatiquement.
output string La réponse finale de l’agent une fois la boucle de raisonnement terminée. Si vous avez besoin de données structurées, demandez à l’agent dans le prompt de formater sa réponse en JSON et parsez-la en aval avec un JSON Path Extractor.
Exemples d’utilisation
Cas 1 : Q&A ancré sur une base de connaissances privée
Vous voulez que l’agent réponde aux questions support strictement à partir de votre documentation.
Configuration :
- Model name : un LLM avec capacités de raisonnement (classe GPT-4 par exemple).
- System Message :
You are a support assistant. Only answer using information from the
attached knowledge base. If the answer is not in the sources, say
"I don't know based on the available documentation."- prompt :
Question from the customer: {{customer_question}}
Search the knowledge base, then provide:
- A concise answer (max 4 sentences)
- The 1-3 most relevant source titles you used- RAG : sélectionnez votre datasource « Product docs ».
- Tools / MCP Servers : aucun — l’agent doit s’appuyer uniquement sur le RAG.
Cas 2 : Recherche multi-étapes avec outils et MCP
Vous voulez que l’agent enrichisse un lead en combinant des outils web et un CRM interne exposé via MCP.
Configuration :
- prompt :
Enrich the lead {{lead_email}}:
1. Use the web search tool to find the company website from the email domain.
2. Scrape the homepage and "About" page to extract industry, size, and value proposition.
3. Call the CRM MCP server to check whether this account already exists.
4. Return a JSON object with keys: company_name, website, industry, size_estimate, exists_in_crm, summary.
Use at most 8 tool calls. If a step fails, continue with whatever information you have.- Tools : Web Search, Web Scraper.
- MCP Servers : votre serveur CRM interne.
- Temperature :
0.3pour rendre la sélection d’outils reproductible.
Problèmes courants
Le node échoue à la validation avec 'Agent requires instructions to be configured'
Cause : Le champ prompt est vide ou ne contient que des espaces.
Solution : Ouvrez les paramètres du node et remplissez le champ prompt avec la tâche à effectuer. Le validateur supprime les espaces, donc un simple espace ne suffit pas.
L'agent boucle, refait le même appel d'outil ou ne termine jamais
Cause : Les instructions ne définissent pas de condition d’arrêt claire, ou le modèle est trop faible pour planifier de manière fiable.
Solution : Ajoutez un budget explicite dans le prompt (« Use at most N tool calls », « If you cannot find X, say so and stop »). Passez sur un modèle de raisonnement plus puissant. Baissez Temperature à 0,2–0,4.
La réponse finale est tronquée
Cause : Max output tokens est trop bas pour le format demandé, ou l’agent a consommé son budget en raisonnement intermédiaire.
Solution : Augmentez Max output tokens. Demandez à l’agent dans le prompt une réponse plus courte et structurée. Pour les modèles de raisonnement, augmentez aussi Thinking Budget si la troncature survient pendant le thinking.
La connexion d'un node File échoue avec une erreur de type de fichier
Cause : Le node Agent n’accepte que les Structured Documents (csv, xlsx, json, xml) et Unstructured Documents (pdf, txt, md, docx, pptx) provenant d’un node File input. Les autres types sont rejetés à la connexion.
Solution : Modifiez le type du node File pour un type supporté, ou pré-traitez le fichier avec un node de conversion avant de l’envoyer à l’agent.
L'agent ignore mes datasources ou serveurs MCP
Cause : Les instructions ne les mentionnent pas, donc l’agent ne sait pas qu’ils sont disponibles — ou il les a jugés non pertinents pour la tâche en cours.
Solution : Référencez explicitement la capacité dans le prompt (« Use the knowledge base to answer », « Call the CRM MCP server to verify the account »). Indiquez le nom de la datasource dans le system message.
Bonnes pratiques et pièges à éviter
Traitez le prompt comme un contrat : énoncez l’objectif, les outils autorisés, le budget d’itérations et le format de sortie exact. Des contrats concrets donnent des réponses concrètes ; des prompts vagues donnent des agents qui dérivent.
N’activez pas toutes les capacités « au cas où ». Chaque outil, datasource et serveur MCP supplémentaire élargit l’espace d’actions sur lequel l’agent doit raisonner — runs plus lents, plus de boucles, coût en tokens plus élevé. Attachez uniquement ce que la tâche exige strictement.
Comment s’intègre-t-il dans un workflow ?
Le node AI Agent remplace typiquement une chaîne de nodes LLM + outils dès qu’un raisonnement entre étapes est nécessaire. Voici un schéma typique d’intégration pour un workflow recherche-puis-action :
graph LR
Input[Text Input
<br/>topic or lead] --> Agent[AI Agent
<br/>plans + uses tools/RAG/MCP]
Agent --> FR[Find and Replace
<br/>strip Markdown fences]
FR --> Extractor[JSON Path Extractor]
Extractor --> Writer[Google Docs Writer]Nodes complémentaires
Utilisez un appel LLM simple lorsque la tâche est une génération de texte one-shot sans outils.
Alternative directe lorsque vous avez besoin de contenu scrapé sans raisonnement d’agent, ou pour alimenter la boîte à outils de l’agent.
À placer après l’Agent lorsque vous lui demandez de renvoyer du JSON, pour extraire les champs structurés en aval.
Nettoyez les fences Markdown ou caractères parasites dans la réponse finale de l’agent avant parsing.