Loop
Le node Loop répète une séquence de nodes pour chaque élément d'une liste en entrée, permettant le traitement en lot sur des tableaux.
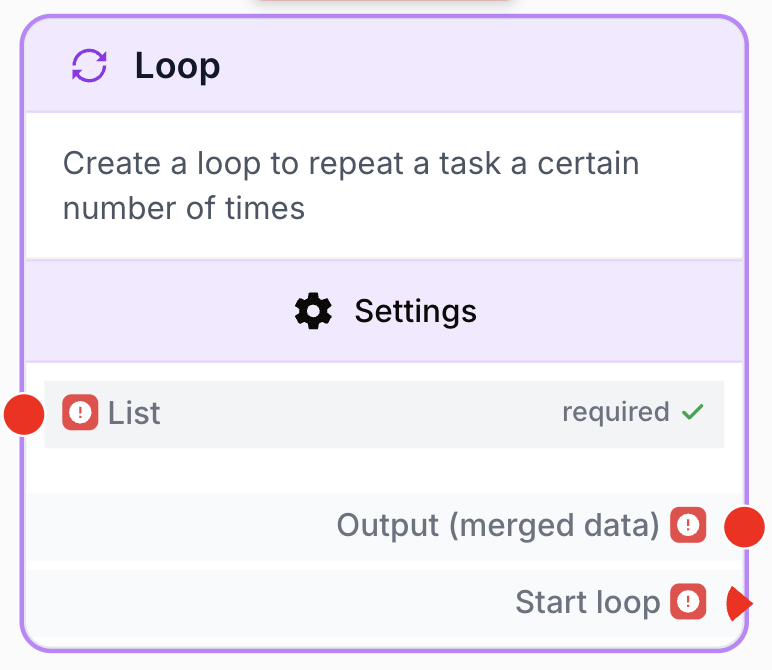
À quoi sert le node Loop ?
Le node Loop (libellé : Loop Node) parcourt une liste et exécute la branche aval une fois par élément. C’est un node de contrôle de flux : connectez une liste à son entrée, branchez le sous-workflow par itération sur sa sortie Start loop, et récupérez les résultats agrégés sur sa sortie Output (merged data) une fois la boucle terminée.
Cas d’usage typiques :
- Scraper une liste d’URL provenant de Google Sheets, d’une API ou d’une liste manuelle.
- Parcourir des lignes de feuille de calcul pour les enrichir, les transformer ou les envoyer une à une.
- Appliquer un prompt LLM à chaque entrée d’un tableau (titres, descriptions, produits).
- Démultiplier un appel d’intégration (HubSpot, BigQuery, WordPress) sur un lot d’enregistrements.
Configuration rapide
Suivez ces étapes pour ajouter et configurer le node Loop dans votre workflow :
Ajouter le node au canevas
Ouvrez la bibliothèque de nodes (Node Library), naviguez dans Tools > Flow Control, puis glissez-déposez le node Loop Node sur votre espace de travail.
Connecter la liste en entrée
Reliez la sortie du node amont (Google Sheets, API Connector, Create List, Split List, etc.) au port d’entrée List. La valeur doit être un tableau JSON.
Construire la branche par itération
Reliez la sortie Start loop au premier node du sous-workflow à exécuter pour chaque élément. Dans cette branche, référencez l’élément courant via le placeholder de boucle (par exemple {{Loop_0.currentItem}}).
Paramétrer les limites et la gestion d’erreur
Ouvrez les paramètres du node pour définir Max Iterations (1–100), Delay between iterations (≥ 100 ms) et Error Handling (Skip & Continue ou None).
Exploiter la sortie agrégée
Reliez le port Output (merged data) au node suivant pour consommer le tableau de résultats agrégés depuis chaque itération.
Paramètres de configuration
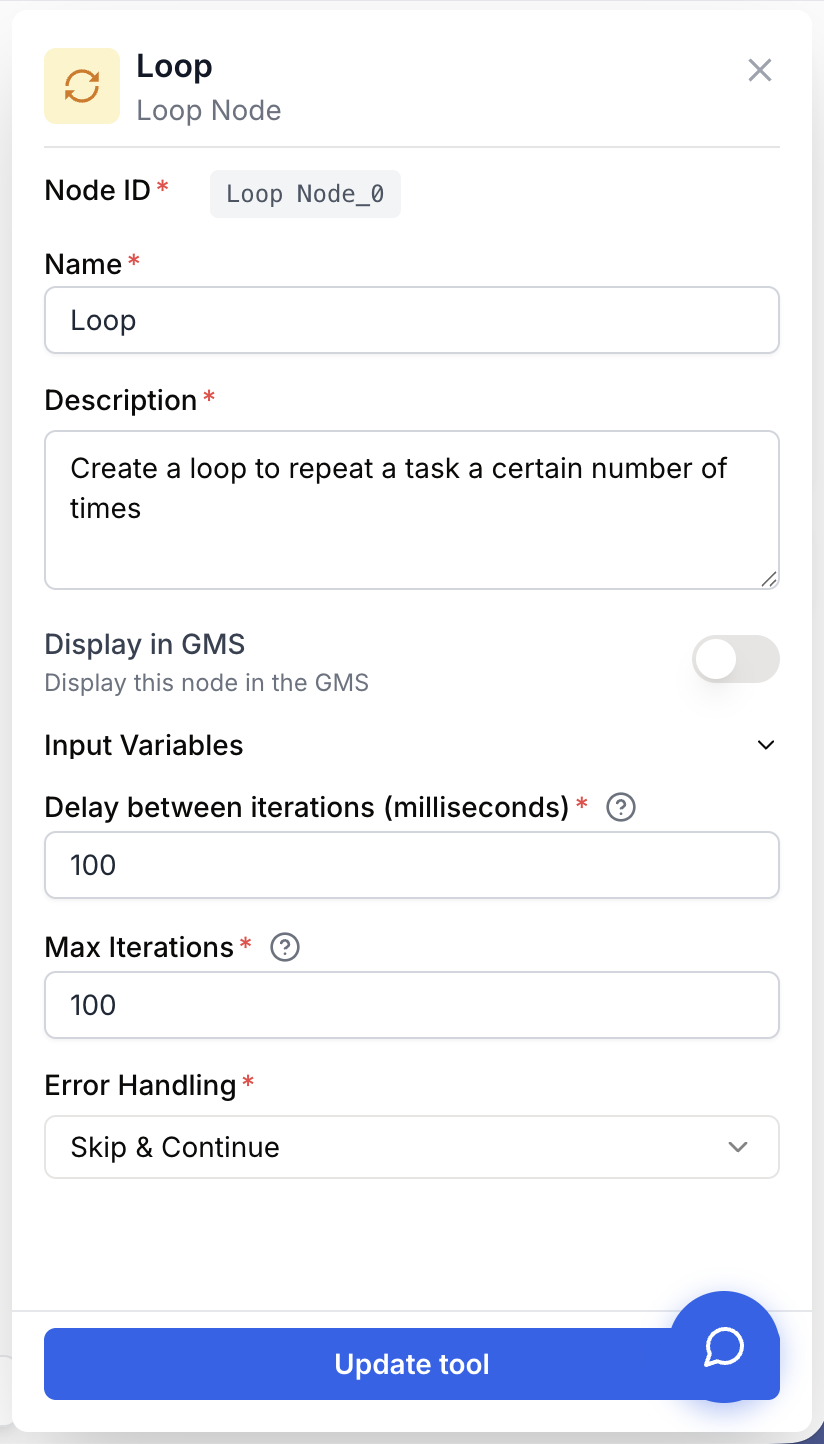
Le node Loop dispose d’une liste d’entrée, de trois paramètres de configuration et de deux sorties. Les réglages sont validés par le formulaire : les valeurs invalides sont refusées avant l’enregistrement.
Champs requis
Name string required default: Loop Nom du node — Identifie le node sur le canevas et dans les placeholders (par exemple Loop_0). Renommez-le (ex. LoopOverUrls) pour rendre les placeholders de la branche interne plus lisibles.
Description string required default: Create a loop to repeat a task a certain number of times. Description du node — Phrase courte décrivant ce sur quoi la boucle itère. Utile pour la documentation et le débogage.
List json required Liste en entrée — Tableau JSON des éléments à parcourir. Provenant d’une sortie d’un node amont ({{GoogleSheets_0.data}}, {{ApiConnector_0.body.results}}) ou d’une liste statique (["a", "b", "c"]). Le runner lève « Loop node does not have a valid input list » si la valeur ne peut pas être parsée comme JSON.
Champs optionnels
Delay between iterations (milliseconds) number default: 100 Délai inter-itérations — Pause insérée entre deux itérations consécutives, en millisecondes. Minimum : 100 ms. Augmentez-le (1000–3000 ms) lorsque la branche interne sollicite des API externes pour éviter le rate limiting.
Max Iterations number default: 100 Nombre maximum d’itérations — Plafond strict du nombre d’itérations exécutées. Plage : 1 à 100. Si la liste d’entrée dépasse cette valeur, seuls les N premiers éléments sont traités.
Error Handling string default: Skip Stratégie de gestion d’erreur — Comportement de la boucle face à un échec dans une itération.
Skip— Skip & Continue : l’itération en échec est ignorée, la boucle passe à l’élément suivant. Par défaut.None— La boucle s’arrête à la première erreur et l’ensemble du workflow échoue.
Conservez Skip & Continue pour les traitements en lot où un succès partiel est acceptable (scraping, enrichissement). Passez à None lorsque chaque élément est critique (écritures financières, e-mails transactionnels) afin qu’un échec remonte immédiatement.
Que renvoie le node ?
Le node Loop expose deux ports de sortie. Connectez chacun à la branche aval appropriée.
Start loop json Déclencheur par itération. Branchez ici le premier node de votre sous-workflow. Dans la branche, l’élément courant est exposé via les placeholders Loop (typiquement {{Loop_0.currentItem}}, {{Loop_0.index}}, {{Loop_0.totalItems}}).
Output (merged data) json Tableau agrégé des résultats, disponible une fois la boucle terminée. Chaque entrée correspond à une itération, dans l’ordre d’entrée. Les itérations ignorées (lorsque Error Handling = Skip) sont exclues du tableau agrégé.
Comment récupérer l’output ?
Dans Draft & Goal, vous n’avez pas besoin de chercher un nom de variable complexe généré par le système. Pour exploiter le résultat :
- Tirez un lien depuis le port Output (merged data) du node Loop.
- Connectez-le à l’entrée du node suivant (Filter List, JSON Path Extractor, Sheets Writer, etc.).
- Dans ce node suivant, créez et nommez votre propre variable (par exemple,
loop_results). Le tableau agrégé y sera automatiquement injecté.
Exemples d’utilisation
Cas 1 : Scraper une liste d’URL depuis Google Sheets
Vous lisez une liste d’URL dans une Google Sheet, scrapez chaque page, puis réécrivez le contenu nettoyé dans une feuille.
graph LR
A[Google Sheets reader] --> B[Loop Node]
B --> C[Web Scraper]
C --> D[HTML Cleaner]
D --> E[Sheets writer]
B --> EConfiguration :
List={{GoogleSheets_0.data}}Max Iterations=100Delay between iterations=2000(2 secondes, scraping respectueux)Error Handling=Skip
Dans la branche de boucle :
- URL du Web Scraper =
{{Loop_0.currentItem.url}}
Cas 2 : Envoyer un e-mail personnalisé à chaque contact
Vous itérez sur une liste de contacts, générez un message personnalisé avec un LLM, puis l’envoyez via le node Email Sender. Un destinataire en échec ne doit pas bloquer le reste.
graph LR
A[Create List of contacts] --> B[Loop Node]
B --> C[LLM personalize]
C --> D[Email Sender]
B --> E[Log results]Configuration :
List={{CreateList_0.list}}Max Iterations=100Delay between iterations=1000Error Handling=Skip
Dans la branche de boucle :
- Variable du prompt LLM =
{{Loop_0.currentItem.name}} - Champ
tode l’Email Sender ={{Loop_0.currentItem.email}}
Problèmes courants
Le workflow échoue avec : Loop node does not have a valid input list
Cause : La valeur connectée à List ne peut pas être parsée comme un tableau JSON. Le node amont a envoyé une chaîne, un objet, ou un payload vide / null.
Solution : Vérifiez que la sortie amont est bien un tableau JSON. Encadrez une valeur manuelle avec ["..."]. Pour Google Sheets, pointez sur le tableau data des lignes. Pour une réponse d’API, ciblez le champ qui contient réellement la liste (par exemple body.results).
Seuls les 100 premiers éléments sont traités
Cause : Max Iterations est plafonné à 100 par le formulaire de paramètres. Toute liste de plus de 100 éléments est tronquée.
Solution : Découpez l’entrée en amont avec le node Split List en lots de 100 éléments maximum, puis chaînez plusieurs Loop. Pour des jeux de données très volumineux, paginez en amont (pagination Sheets, pagination API) et lancez le workflow par lot.
La boucle est trop lente / met plusieurs minutes pour une petite liste
Cause : Delay between iterations est élevé, ou la branche par itération contient des nodes lents (LLM, scraping).
Solution : Abaissez le délai à son minimum (100 ms) si aucune contrainte de rate limiting externe ne s’applique. Profilez la branche interne et supprimez ou mettez en cache les étapes lentes lorsque c’est possible.
Une itération échoue et arrête tout le workflow
Cause : Error Handling est positionné sur None. La première erreur interrompt la boucle et fait échouer l’exécution.
Solution : Passez Error Handling à Skip & Continue pour que l’exécution survive aux échecs individuels. Ajoutez un node Conditional dans la branche pour journaliser ou router les éléments en échec.
La sortie agrégée est vide alors que la boucle s'est exécutée
Cause : La branche interne n’a produit aucune sortie, ou toutes les itérations ont été ignorées suite à des erreurs.
Solution : Ouvrez l’historique d’exécution, inspectez chaque itération, confirmez que les nodes internes renvoient bien des données. Basculez temporairement Error Handling sur None pour faire remonter l’erreur sous-jacente.
Bonnes pratiques et pièges à éviter
Renommez le node Loop (par exemple LoopOverContacts) avant de construire la branche interne — les placeholders dans la branche référencent le nom du node, donc un nom clair rend {{LoopOverContacts_0.currentItem.email}} auto-explicatif.
N’imbriquez pas des Loops aveuglément. Deux nodes Loop imbriqués multiplient les itérations : 50 catégories × 50 produits = 2 500 itérations, mais chaque Loop est plafonné à 100. Planifiez la limite à chaque niveau et pré-agrégez quand c’est possible pour rester sous le plafond de 100 itérations.
Comment s’intègre-t-il dans un workflow ?
Le node Loop se place entre un node producteur de liste et une branche de traitement par élément, puis ré-agrège les résultats en aval. Schéma typique :
graph LR
Source[Google Sheets / API / Create List] --> Loop[Loop Node]
Loop -->|Start loop| Inner[Branche par élément
<br/>scrape / LLM / écriture]
Loop -->|Output merged data| After[Agrégateur
<br/>Filter / JSON Path / Sheets]Nodes complémentaires
Logique de branchement à l’intérieur du Loop pour router les éléments selon une condition avant traitement.
Découpez une grande liste en lots de ≤ 100 éléments pour que chaque lot tienne dans le plafond d’itérations du Loop.
Construisez un tableau statique ou dynamique à injecter directement dans l’entrée du Loop.
Filtrez la sortie agrégée du Loop pour ne conserver que les itérations qui satisfont une règle.
Comptez les entrées de la sortie agrégée du Loop pour le reporting ou le branchement.