Text Counter
Comptez les mots, caractères, phrases et estimez les tokens dans une chaîne de texte avec des métriques sélectionnables.
Nouveautés — Avril 2026 — Vous pouvez désormais choisir quelles métriques calculer. Le comptage de tokens utilise le tokenizer o200k_base pour une estimation précise. Ajout d’options de gestion des erreurs.
À quoi sert le node Text Counter ?
Le node Text Counter analyse une chaîne de texte et retourne des statistiques sur son contenu. Vous choisissez quelles métriques calculer — seules celles sélectionnées apparaissent comme sorties sur le node.
Cas d’usage courants :
- Valider la longueur du contenu avant publication (ex. : meta descriptions de moins de 160 caractères)
- Vérifier les objectifs de nombre de mots pour les articles SEO
- Estimer l’utilisation de tokens avant d’envoyer du texte à un LLM
- Compter les phrases pour évaluer la lisibilité du contenu
Configuration rapide
Ajoutez le node au canvas
Ouvrez la bibliothèque de nodes, allez dans Tools > Text Processing, puis glissez-déposez le node Text Counter sur votre espace de travail.
Connectez l’entrée
Connectez le port d’entrée à la sortie du node contenant le texte à analyser (ex. : un node LLM, un Text Input, ou un Web Scraper).
Sélectionnez vos métriques
Ouvrez les paramètres du node. Dans la section Metrics, activez les comptages dont vous avez besoin. Par défaut, seul Word Count est activé. Vous devez garder au moins une métrique active.
Connectez les sorties
Chaque métrique activée crée son propre port de sortie sur le node. Connectez-les aux nodes suivants de votre workflow.
Paramètres de configuration
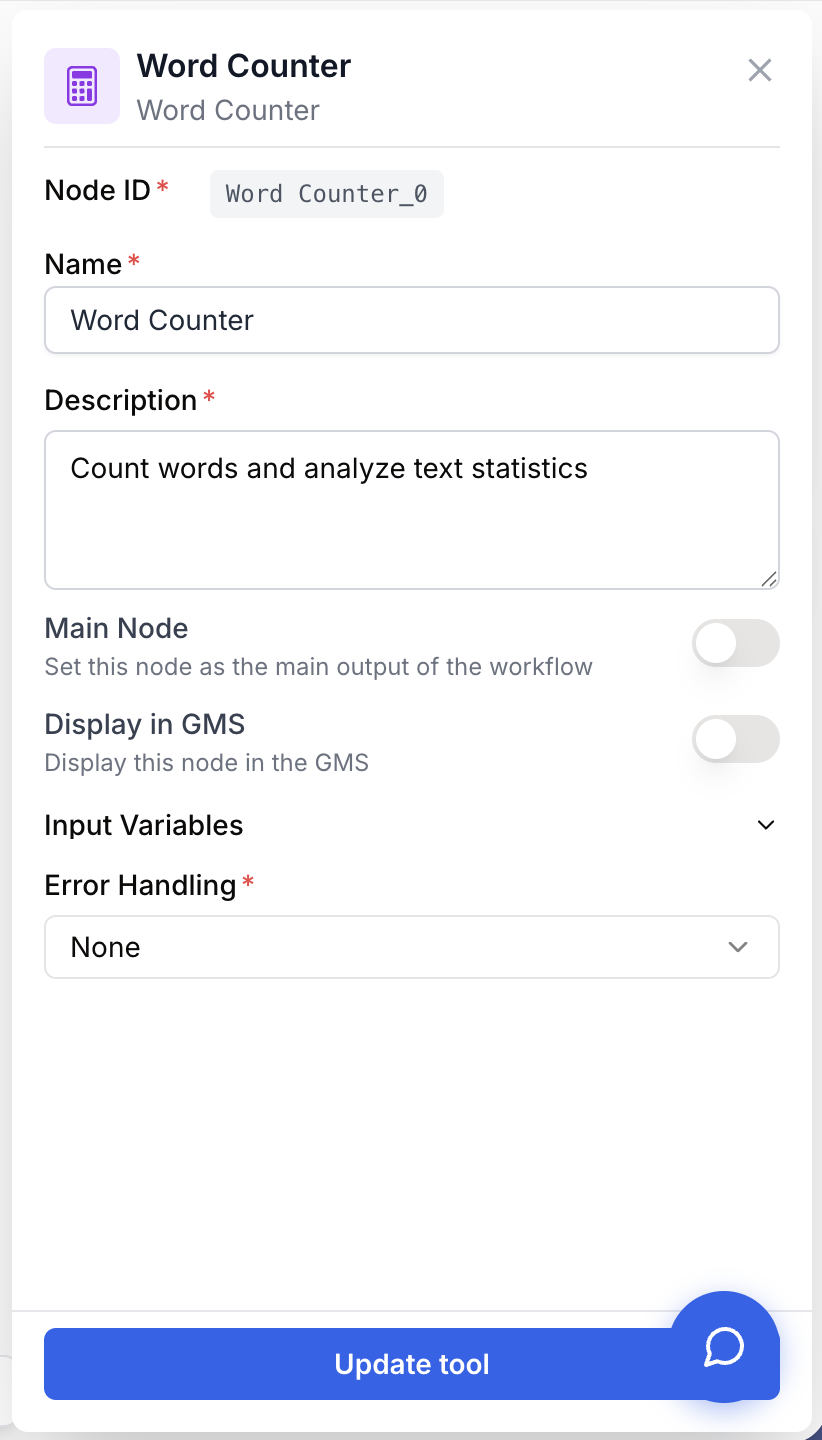
Champs obligatoires
Text string required Le texte à analyser. Connectez-le à n’importe quel node qui produit du contenu texte.
Métriques
Activez ou désactivez les statistiques que le node doit calculer. Seules les métriques activées apparaissent comme ports de sortie.
Word Count toggle default: Activé Nombre de mots dans le texte.
Character Count toggle default: Désactivé Nombre total de caractères (hors retours à la ligne).
Characters (no spaces) toggle default: Désactivé Nombre de caractères en excluant tous les espaces.
Sentence Count toggle default: Désactivé Nombre de phrases, détectées par la ponctuation (., !, ?).
Token Count toggle default: Désactivé Estimation du nombre de tokens avec le tokenizer o200k_base (utilisé par GPT-4o et modèles similaires). Le nombre réel peut varier selon le modèle d’IA utilisé.
Gestion des erreurs
Error Handling select default: None Contrôle le comportement du node en cas d’erreur.
- None — Le node s’arrête et l’exécution du workflow échoue.
- Skip & Continue — Le node retourne
0pour toutes les métriques et continue l’exécution.
Que produit le node en sortie ?
Quand une seule métrique est activée, le node retourne directement sa valeur sous forme de chaîne.
Quand plusieurs métriques sont activées, chacune est disponible comme une sortie nommée distincte :
Word Count string Nombre de mots trouvés dans le texte.
Character Count string Nombre total de caractères (hors retours à la ligne).
Characters (no spaces) string Nombre de caractères en excluant tous les espaces.
Sentence Count string Nombre de phrases détectées.
Token Count string Estimation du nombre de tokens avec le tokenizer o200k_base.
Exemples d’utilisation
Exemple 1 : Valider le nombre de mots d’un article
Vous souhaitez vérifier qu’un article généré par un LLM atteint un nombre minimum de mots avant publication.
Texte en entrée : Un article de blog de 1 200 mots sur la stratégie SEO.
Métriques activées : Word Count uniquement.
Sortie : 1200
Connectez cette sortie à un node Conditional pour vérifier si le comptage atteint votre seuil (ex. : >= 1000).
Exemple 2 : Estimer le coût en tokens avant un appel LLM
Vous souhaitez vérifier combien de tokens un prompt va consommer avant de l’envoyer à un modèle coûteux.
Texte en entrée : Un long prompt système + contexte utilisateur.
Métriques activées : Word Count + Token Count.
Sorties :
- Word Count :
850 - Token Count :
1124
Utilisez le nombre de tokens pour décider s’il faut tronquer, résumer ou basculer vers un modèle moins cher.
Problèmes courants
Le node retourne 0 pour toutes les métriques
Cause : Le texte en entrée est vide ou ne contient que des espaces.
Solution : Vérifiez la connexion au node précédent. Assurez-vous qu’il produit du contenu texte non vide. Vous pouvez ajouter un node Conditional avant le Text Counter pour ignorer les entrées vides.
Le nombre de tokens ne correspond pas au comptage de mon fournisseur LLM
Cause : Le Text Counter utilise le tokenizer o200k_base (famille GPT-4o). Différents modèles utilisent différents tokenizers — Claude, Gemini, Mistral et les anciens modèles GPT produiront des comptages différents.
Solution : Utilisez le nombre de tokens comme une estimation. Pour un comptage exact, référez-vous à la documentation du tokenizer de votre modèle spécifique.
Bonnes pratiques
N’activez que les métriques dont vous avez réellement besoin. Désactiver Token Count quand vous n’en avez pas besoin évite de charger le tokenizer, ce qui rend le node plus rapide.
Utilisez la gestion d’erreur Skip & Continue quand le Text Counter fait partie d’un workflow de traitement en masse — cela évite qu’une seule entrée vide ne stoppe l’ensemble de l’exécution.
Nodes associés
Générez du contenu texte, puis utilisez le Text Counter pour valider sa longueur ou estimer l’utilisation de tokens.
Nettoyez le texte avant le comptage — supprimez les caractères ou le formatage indésirables qui pourraient fausser vos métriques.
Orientez votre workflow en fonction de seuils de nombre de mots ou de tokens.