Google BigQuery Writer
Le node Google BigQuery Writer execute des requetes SQL INSERT, UPDATE, MERGE et DELETE sur les tables BigQuery pour ecrire les donnees de votre workflow dans votre entrepot de donnees.
Nouveautés — Mai 2026 — Le Writer accepte désormais un tableau d’objets JSON comme variable de template et l’expanse en un INSERT ... VALUES (...), (...), ... multi-lignes en une seule requête. Les grands tableaux sont auto-chunkés (plafond de 800 000 octets par requête et 1 000 lignes par requête — limite douce documentée de BigQuery), et chaque chunk porte un token d’idempotence stable pour qu’un rejeu côté runner ne double pas les insertions. Envelopper le node dans une Loop n’est plus nécessaire pour les insertions en masse.
À quoi sert le node Google BigQuery Writer ?
Le node Google BigQuery Writer exécute des requêtes SQL DML (Data Manipulation Language) sur vos tables BigQuery. Il prend en charge les quatre opérations d’écriture standard — INSERT, UPDATE, MERGE et DELETE — afin de persister la sortie d’un workflow, synchroniser des données externes ou maintenir vos tables d’entrepôt alignées avec les sources amont.
Cas d’usage typiques :
- Insérer des lignes générées par un LLM (briefs d’articles, classifications, embeddings) dans une table d’analyse BigQuery
- Mettre à jour des enregistrements existants à partir de résultats d’enrichissement issus de nodes API ou de scraping
- Fusionner des résultats de scraping incrémentaux dans un catalogue dédupliqué via
MERGE - Supprimer des lignes obsolètes qui ne correspondent plus à une source de vérité amont
Configuration rapide
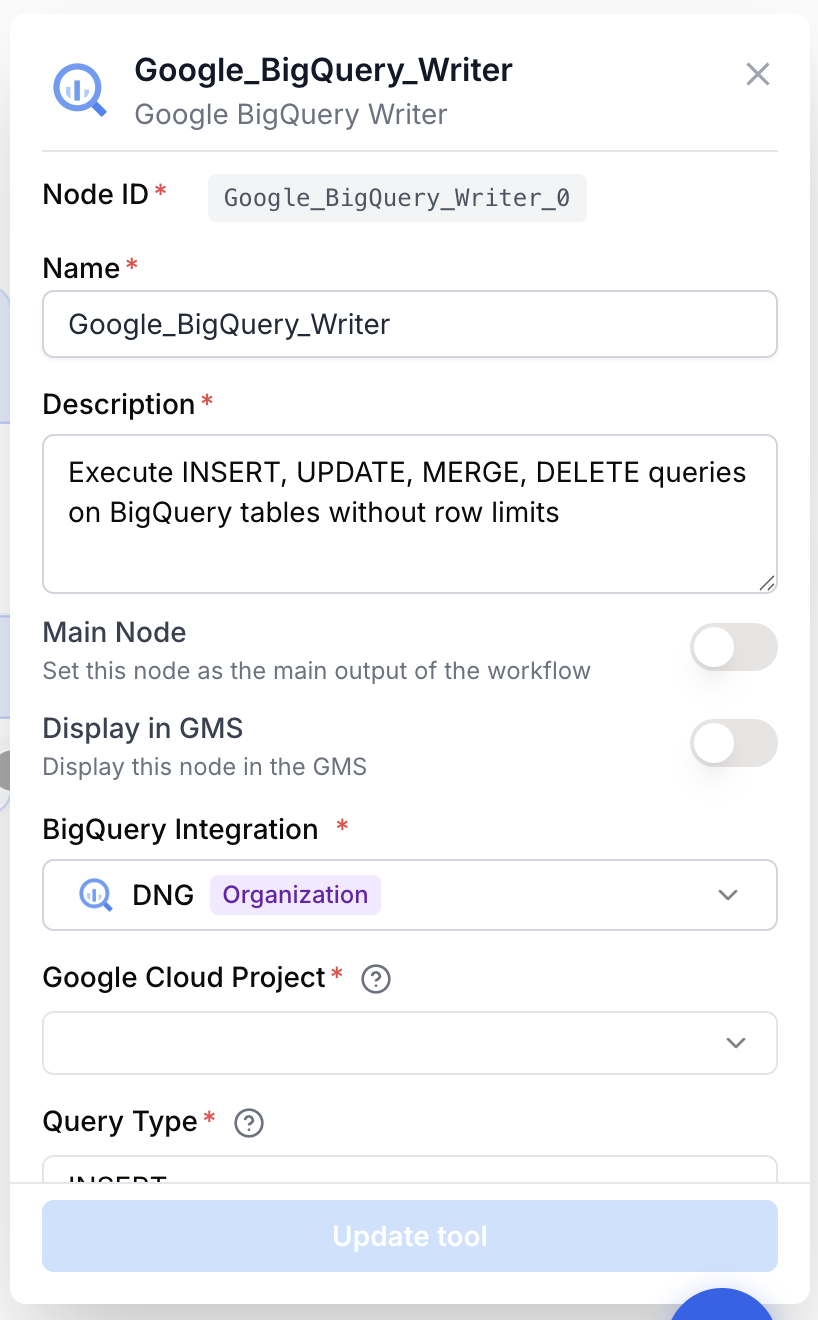
Connectez votre intégration BigQuery
Ouvrez les paramètres du node et sélectionnez votre intégration BigQuery. Si aucune n’est encore connectée, rendez-vous dans Settings > Integrations > Google BigQuery et authentifiez-vous avec le compte Google propriétaire du projet cible.
Choisissez le projet Google Cloud
Sélectionnez le projet Google Cloud contenant votre dataset dans la liste déroulante. La liste est récupérée en direct depuis le compte connecté ; seuls les projets accessibles s’y affichent.
Choisissez le type de requête
Sélectionnez le Query Type correspondant à la requête SQL que vous voulez exécuter : INSERT, UPDATE, MERGE ou DELETE. Il doit correspondre au verbe en début de requête — le validateur rejette les écarts.
Rédigez la requête SQL
Saisissez la BigQuery SQL Query en SQL standard BigQuery. Référencez les sorties des nodes en amont avec la syntaxe {{variable_name}} — les valeurs sont interpolées à l’exécution. Encadrez toujours les identifiants de table avec des accents graves : `project.dataset.table`.
Paramètres de configuration
Champs obligatoires
integration_id integration required Intégration BigQuery — La connexion au compte Google utilisée pour s’authentifier auprès de l’API BigQuery. L’intégration doit disposer du rôle BigQuery Data Editor (ou équivalent) sur le dataset cible.
google_cloud_project string required Projet Google Cloud — L’ID du projet GCP hébergeant le dataset et la table où écrire. Sélectionné depuis une liste déroulante alimentée par l’intégration ; peut aussi être templé via {{project_id}} depuis un node amont.
query_type string required default: insert Query Type — L’opération DML à exécuter. Une valeur parmi insert, update, merge, delete. Doit correspondre au verbe en tête de la requête SQL.
sql_query string required BigQuery SQL Query — L’instruction DML à exécuter. Supporte le templating {{variable}} pour les valeurs amont. Exemple : INSERT INTO `my_proj.my_dataset.events` (id, label) VALUES ('{{row_id}}', '{{label}}').
Les variables de template comme {{title}}, {{score}} ou {{json_payload}} sont remplacées par les valeurs des nodes amont avant l’envoi de la requête à BigQuery. Encadrez les valeurs de type chaîne avec des apostrophes simples dans le SQL lui-même.
Que produit le node en sortie ?
Le node renvoie une chaîne JSON décrivant le job BigQuery exécuté : nombre de lignes affectées, ID du job et métadonnées d’exécution. Il n’y a aucune limite de lignes en écriture.
{
"affected_rows": 124,
"job_id": "bq_job_abc123",
"query_type": "insert",
"status": "success"
}execution_result string Une chaîne JSON contenant les informations d’exécution : nombre de lignes affectées, ID du job BigQuery, type de requête et statut. Connectez cette sortie à un node aval et liez-la à un nom de variable (par exemple bq_result) pour inspecter ou journaliser le résultat de l’écriture.
Insertions en masse via un input array
Si un node amont émet un tableau d’objets JSON (sortie collectée d’une Loop, liste renvoyée par un Code Block, aggregated_results d’un node HTTP, etc.), vous pouvez l’envoyer directement à une variable de template et le Writer l’expansera en un INSERT multi-lignes :
INSERT INTO `acme-analytics.events.raw` (id, payload, ts)
VALUES {{rows}}où {{rows}} est [{ "id": ..., "payload": ..., "ts": ... }, ...]. Le Writer détecte la forme array, prend l’ordre des colonnes depuis la liste du SQL, et rend chaque élément comme un tuple VALUES (...).
Auto-chunking — quand le SQL rendu dépasserait l’un des deux plafonds de sécurité, le Writer scinde le tableau en plusieurs requêtes consécutives :
| Plafond | Valeur | Pourquoi |
|---|---|---|
| Octets max par requête | 800 000 | Reste sous la limite de taille par requête de BigQuery |
| Lignes max par requête | 1 000 | Limite douce documentée de BigQuery sur les tuples VALUES |
Tokens d’idempotence — chaque chunk porte un token stable dérivé de l’identité workflow/run, donc un rejeu transparent par le runner (redelivery NATS, erreur API transitoire) ne double pas les insertions. Le token survit aux frontières de chunk — les chunks 1, 2, 3 d’un même appel logique référencent tous le même token.
L’auto-chunking et l’idempotence sont transparents — votre SQL ne change pas. Le affected_rows en sortie reporte le total sur tous les chunks ; job_id est celui du dernier chunk (un Job par chunk côté BigQuery).
Exemples d’utilisation
Exemple 1 : Insérer des lignes classifiées par un LLM dans une table analytique
Vous avez un node LLM qui classe les tickets de support entrants et vous voulez persister chaque résultat dans BigQuery pour le reporting.
Configuration :
- Query Type :
insert - SQL Query :
INSERT INTO `acme-analytics.support.ticket_classifications`
(ticket_id, category, urgency, classified_at)
VALUES
('{{ticket_id}}', '{{category}}', '{{urgency}}', CURRENT_TIMESTAMP())Placez ce node dans une Loop pour que chaque ticket de la liste amont produise une ligne insérée.
Exemple 2 : Fusionner des données produit scrapées dans un catalogue
Vous scrapez quotidiennement les pages produit de concurrents et voulez upserter les données les plus fraîches dans un catalogue maître sans dupliquer de lignes.
Configuration :
- Query Type :
merge - SQL Query :
MERGE `acme-data.catalog.products` AS T
USING (SELECT '{{sku}}' AS sku, '{{title}}' AS title, {{price}} AS price) AS S
ON T.sku = S.sku
WHEN MATCHED THEN UPDATE SET title = S.title, price = S.price, updated_at = CURRENT_TIMESTAMP()
WHEN NOT MATCHED THEN INSERT (sku, title, price, updated_at)
VALUES (S.sku, S.title, S.price, CURRENT_TIMESTAMP())Exemple 3 : Supprimer des enregistrements obsolètes par liste d’IDs
Après une étape de réconciliation produisant une liste d’IDs de tickets à supprimer, exécutez un DELETE pour nettoyer l’entrepôt.
Configuration :
- Query Type :
delete - SQL Query :
DELETE FROM `acme-analytics.support.tickets`
WHERE ticket_id = '{{ticket_id}}'Exemple 4 : Insertion en masse avec une variable array
Votre pipeline amont a collecté des centaines de lignes classifiées par un LLM dans un seul tableau. Au lieu de boucler ligne par ligne, envoyez le tableau entier comme une seule variable de template :
Configuration :
- Query Type :
insert - SQL Query :
INSERT INTO `acme-analytics.support.ticket_classifications`
(ticket_id, category, urgency, classified_at)
VALUES {{rows}}où {{rows}} est [{"ticket_id": "T-1", "category": "billing", "urgency": "high", "classified_at": "2026-05-27T10:00:00Z"}, ...].
Le Writer rend le tableau comme un bloc VALUES multi-lignes, auto-chunke s’il dépasse 800 Ko ou 1 000 lignes, et tagge chaque chunk avec un token d’idempotence pour des rejeux sûrs.
Problèmes courants
Erreur de validation : la requête SQL doit commencer par INSERT, UPDATE, MERGE ou DELETE
Cause : La requête commence par un verbe non-DML (par ex. SELECT, CREATE) ou contient des espaces ou commentaires en tête avant le verbe.
Solution : Utilisez le node BigQuery Reader pour les requêtes SELECT. Pour le DDL, exécutez-le manuellement ou via un autre outil. Assurez-vous que le premier token non-blanc de la requête soit INSERT, UPDATE, MERGE ou DELETE.
Erreur : l'intégration BigQuery n'est pas configurée
Cause : Aucune intégration n’est sélectionnée dans les paramètres du node, ou l’intégration sélectionnée a été révoquée.
Solution : Ouvrez les paramètres du node et sélectionnez une intégration BigQuery valide. Si une fenêtre d’intégration révoquée s’affiche, réautorisez l’accès depuis Settings > Integrations.
Erreur : ID du projet Google Cloud manquant
Cause : La liste déroulante du projet est vide, ou la variable amont liée à google_cloud_project se résout en chaîne vide à l’exécution.
Solution : Choisissez explicitement un projet dans la liste déroulante, ou vérifiez que le node amont produisant l’ID de projet émet bien une valeur non vide avant l’exécution de ce node.
Permission refusée ou 403 depuis l API BigQuery
Cause : Le compte de service ou l’utilisateur connecté ne dispose pas de bigquery.tables.updateData (ou équivalent) sur le dataset cible.
Solution : Attribuez le rôle BigQuery Data Editor sur le dataset, ou un rôle personnalisé incluant la permission DML manquante, au principal utilisé par votre intégration.
"Array input is empty — cannot build a multi-row VALUES clause"
Cause : La variable de template liée à une clause VALUES {{rows}} se résout en tableau vide au runtime.
Solution : Garder le Writer derrière un node Conditional en amont qui skip l’exécution si le tableau est vide. Ou filtrer le pipeline amont pour garantir au moins un élément avant l’invocation du Writer.
Un élément du tableau n'est pas un objet JSON
Cause : Le tableau contient un scalaire (string, number) ou un tableau imbriqué au lieu d’objets { clé: valeur }. Le Writer ne peut rendre que des dicts comme tuples VALUES (...) — le mapping colonne-vers-clé requiert un objet plat.
Solution : Wrapper chaque élément pour qu’il devienne {"col1": value, ...}. Un Code Block en amont est la transformation habituelle.
affected_rows inférieur à la longueur du tableau
Cause : Probablement bénin — l’auto-chunking a tourné mais un chunk a échoué et le Writer reporte un total partiel. Vérifier les logs runner pour l’ID de job du chunk échoué et l’erreur BigQuery.
Solution : Investiguer l’erreur par-chunk dans BigQuery. Les tokens d’idempotence rendent un rejeu manuel du chunk échoué sûr (pas de risque de doubler les chunks déjà committés).
Bonnes pratiques
Préférez les inputs array à la Loop pour les insertions en masse. Envoyer un tableau de JSON en un seul appel au Writer réduit drastiquement les allers-retours API vs. envelopper le node dans une Loop (un appel par ligne). Les Loops restent utiles quand vous avez besoin d’un error handling par ligne ou quand le SQL lui-même varie par ligne ; pour des inserts en masse purs avec un schéma fixe, le chemin array est plus rapide et moins cher.
Validez les templates au préalable — exécutez votre workflow avec un node Text Input alimentant des valeurs d’exemple pour confirmer que le SQL rendu est syntaxiquement correct avant de cibler des tables de production. Le résultat d’exécution journalisé facilite le debug.
Échappez les chaînes provenant des utilisateurs. Les valeurs de template sont interpolées comme du texte brut ; des apostrophes dans la valeur peuvent casser la requête ou ouvrir des chemins d’injection. Assainissez le contenu amont (par ex. avec un node Find and Replace) avant d’insérer du texte libre dans une requête SQL.
Le DML sur tables partitionnées/clusterisées a un coût. UPDATE, DELETE et MERGE réécrivent les partitions affectées. Filtrez sur la colonne de partition chaque fois que possible pour limiter le coût et le temps d’exécution.
Nodes associés
Lisez des lignes depuis BigQuery avec une requête SELECT — couplez-le au Writer pour bâtir des workflows ETL complets.
Itérez sur un tableau d’éléments et exécutez le BigQuery Writer une fois par élément pour insérer ou mettre à jour de nombreuses lignes.
Générez les lignes ou valeurs à persister, puis écrivez-les dans BigQuery pour l’analytique aval.
Extrayez des champs précis d’un payload JSON amont avant de les lier aux variables de template de votre SQL.