Fasterize Data Storage
Le node Fasterize Data Storage envoie des données JSON clé-valeur vers un dataset Fasterize pour piloter dynamiquement des comportements au niveau du CDN.
À quoi sert le node Fasterize Data Storage ?
Le node Fasterize Data Storage envoie des données JSON clé-valeur (objet ou tableau) vers un dataset Fasterize. Une fois stockées, ces données sont diffusées depuis le CDN Fasterize et peuvent être consommées par des règles edge pour piloter des comportements dynamiques comme l’A/B testing, la personnalisation, les redirections ou les feature flags, sans redéployer le site.
Cas d’usage typiques :
- Pousser des métadonnées SEO par URL (titres, descriptions) calculées par un workflow LLM en amont vers un dataset Fasterize pour les surcharger au niveau de l’edge.
- Synchroniser une liste de réécritures d’URL ou de redirections produite par un workflow de scraping ou de sitemap.
- Stocker des clés de personnalisation (segment, variante, langue) consommées par les règles edge de Fasterize.
- Maintenir une carte de feature flags pilotée par un workflow Draft & Goal plutôt que par un déploiement manuel.
Configuration rapide
Connectez votre intégration Fasterize
Ouvrez les paramètres du node et sélectionnez votre intégration Fasterize dans la liste déroulante. Si elle est absente, rendez-vous dans Settings > Integrations pour ajouter une connexion Fasterize.
Renseignez un Dataset ID
Saisissez le Dataset ID du dataset Fasterize qui recevra les données. Le dataset doit déjà exister côté Fasterize.
Connectez l’entrée JSON
Connectez un node en amont à l’entrée Key-Value Data (JSON). La valeur doit être un objet JSON ({"key":"val"}) ou un tableau JSON d’objets ([{"url":"https://...","prop":"val"}]).
Connectez la sortie
Connectez le port de sortie au node suivant pour transmettre la réponse de l’API (statut, écho du payload stocké) à des fins de log ou de traitement ultérieur.
Paramètres de configuration
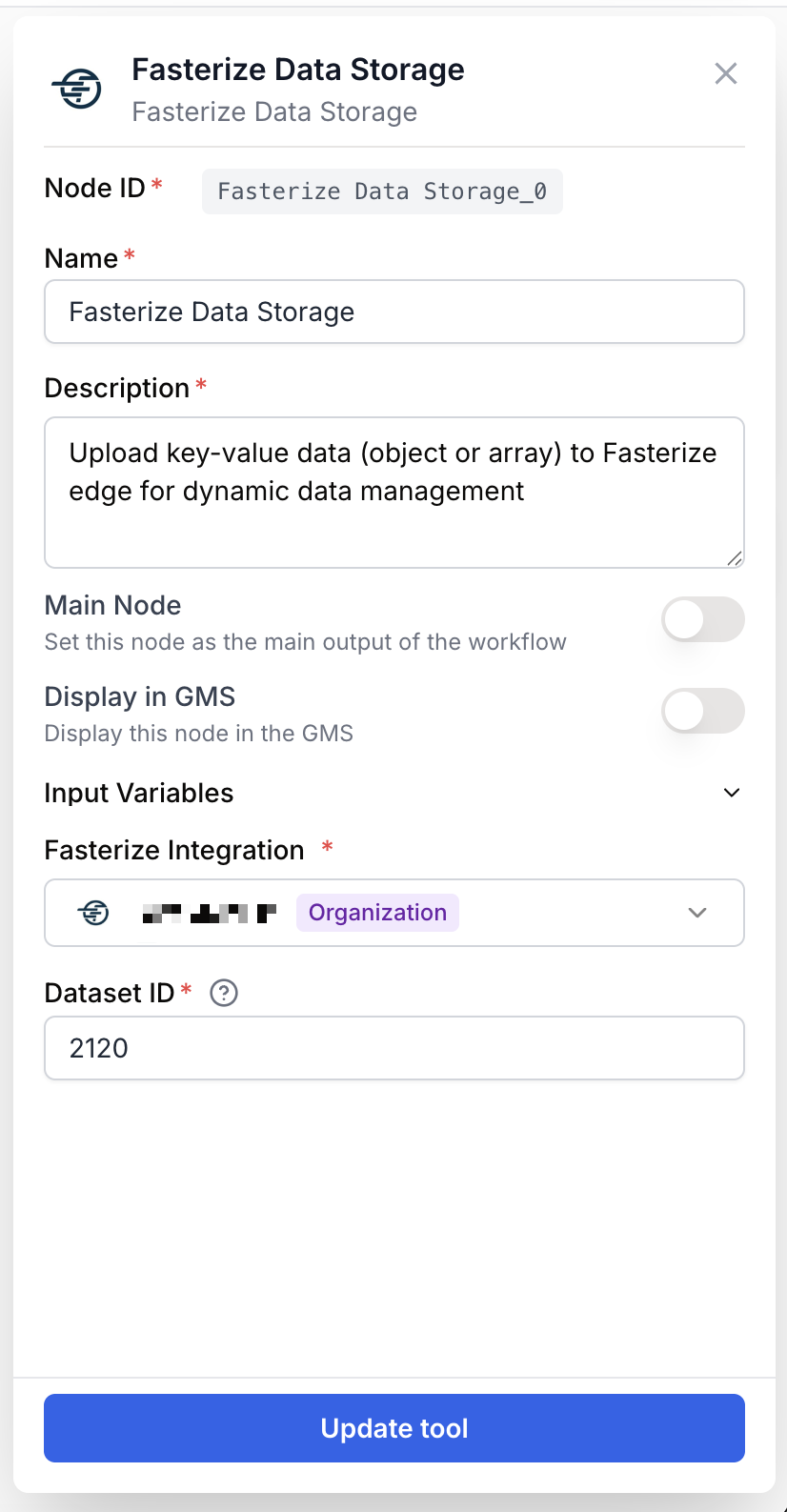
Champs obligatoires
integration_id integration required Intégration Fasterize — Sélectionnez la connexion Fasterize à utiliser. Le runner émet la requête au nom de cette intégration.
dataset_id string required Dataset ID — Identifiant du dataset Fasterize dans lequel les données clé-valeur seront écrites. Peut aussi être fourni dynamiquement via l’entrée dataset_id depuis un node en amont, qui prend la priorité sur le paramètre statique lorsque les deux sont définis.
key_value_data string required Key-Value Data (JSON) — Le payload JSON à envoyer. Accepte un objet JSON ou un tableau d’objets. Fourni en entrée depuis un node en amont ; peut aussi être défini en paramètre statique.
Lorsque le node en amont produit déjà un objet JSON directement (et non sa version sérialisée), le runner le détecte et le sérialise pour vous avant l’envoi à Fasterize.
Que produit le node en sortie ?
Le node renvoie la réponse de l’API Fasterize Data Storage sous forme de chaîne, généralement l’écho des données stockées ou une confirmation de statut.
output string Réponse brute renvoyée par le service Fasterize Data Storage une fois l’upload terminé.
Exemples d’utilisation
Exemple 1 : Pousser des titres SEO générés par LLM vers l’edge
Vous générez des balises <title> optimisées pour une liste d’URL via un workflow LLM et vous voulez que Fasterize les injecte au niveau de l’edge.
Entrée (depuis un node en amont) :
[
{ "url": "https://example.com/blog/seo-2025", "title": "SEO en 2025 : guide pratique" },
{ "url": "https://example.com/blog/edge-personalization", "title": "La personnalisation à l'edge expliquée" }
]Configuration :
- Intégration Fasterize : votre connexion Fasterize
- Dataset ID :
seo_titles_v1 - Key-Value Data (JSON) : connecté à la sortie du LLM ou du JSON Path Extractor
L’edge Fasterize lit alors seo_titles_v1 et réécrit la balise title par URL.
Exemple 2 : Mettre à jour une carte de feature flags depuis un workflow
Vous gérez un petit ensemble de feature flags via un workflow qui résout les variantes selon une date ou une audience.
Entrée :
{
"homepage_hero_variant": "B",
"checkout_express_enabled": true,
"promo_banner": "spring_sale_2025"
}Configuration :
- Dataset ID :
feature_flags - Key-Value Data (JSON) : depuis un node LLM ou Conditional en amont qui construit l’objet
Problèmes courants
Erreur : Dataset ID is required for data storage
Cause : Le paramètre dataset_id est vide et aucune entrée dataset_id n’est connectée.
Solution : Définissez un Dataset ID statique dans les paramètres ou connectez un node en amont fournissant une valeur dataset_id.
Erreur : No key-value data provided for storage
Cause : L’entrée key_value_data est vide ou résolue à {}.
Solution : Vérifiez que le node en amont produit bien un objet ou un tableau JSON non vide, et que la connexion est branchée sur l’entrée Key-Value Data (JSON).
Erreur : Invalid JSON format for key-value data
Cause : La chaîne passée à key_value_data n’est pas un JSON valide (virgules finales, apostrophes simples, caractères non échappés).
Solution : Validez le payload avant ce node, typiquement avec une étape Find and Replace pour nettoyer les fences Markdown ou avec un JSON Path Extractor pour isoler le bon fragment.
Erreur : Key-value data must be a JSON object
Cause : Le JSON parsé est une primitive (string, number, boolean, null) plutôt qu’un objet ou un tableau d’objets.
Solution : Encapsulez la valeur dans un objet, par exemple {"value": "..."}, ou construisez un tableau d’objets en amont.
Bonnes pratiques
Gardez un Dataset ID par responsabilité logique (titres, redirections, flags). Mélanger des clés sans rapport dans le même dataset rend les règles edge plus difficiles à raisonner.
Chaque exécution écrase le dataset avec le payload envoyé. Si vous ne souhaitez en mettre qu’une partie à jour, récupérez d’abord l’état courant, fusionnez, puis envoyez le résultat complet.
Nodes associés
Poussez des listes massives de réécritures d’URL et de redirections vers Fasterize en une seule opération.
Appliquez des recommandations SEO à grande échelle via l’edge Fasterize.
Extrayez le fragment JSON exact à uploader depuis un payload amont plus large.
Générez les valeurs (titres, descriptions, variantes) que vous stockez ensuite dans un dataset Fasterize.