Url
Le node Url crée un champ de saisie d'URL qui déclenche le workflow avec une ou plusieurs adresses web fournies par l'utilisateur.
À quoi sert le node Url ?
Le node Url est un point d’entrée qui capture une ou plusieurs URL fournies par l’utilisateur au lancement du workflow. La valeur capturée est exposée sous forme de chaîne (ou de tableau de chaînes en mode multi-URL), prête à être consommée par des scrapers, API Connectors, outils SEO ou tout autre node qui attend une adresse web.
Cas d’usage typiques :
- Déclencher un Web Scraper ou un HTML Cleaner sur une page cible fournie à l’exécution.
- Alimenter un lot d’URL dans un Loop parallèle pour des audits SEO ou de l’extraction de contenu.
- Pré-remplir une URL par défaut pour les tests tout en laissant l’utilisateur final l’écraser avant l’exécution.
Configuration rapide
Suivez ces étapes pour ajouter et configurer le node Url dans votre workflow :
Ajouter le node au canevas
Ouvrez la bibliothèque de nodes, allez dans la catégorie Input, puis glissez-déposez le node Url sur votre espace de travail.
Choisir mono- ou multi-URL
Ouvrez les paramètres du node. Activez Multiple urls si le workflow doit accepter plusieurs URL en même temps ; laissez-le désactivé pour un champ unique.
Définir les valeurs par défaut et l’obligation
Renseignez éventuellement une Default Value pour pré-remplir le champ. Gardez Required activé pour bloquer toute exécution sans URL, ou désactivez-le si une saisie vide est acceptable en aval.
Connecter la sortie
Reliez le port de sortie (à droite du node) au node suivant (Web Scraper, API Connector, Loop, etc.). Le node consommateur récupère l’URL via la référence standard {{Url_0.output}}.
Paramètres de configuration
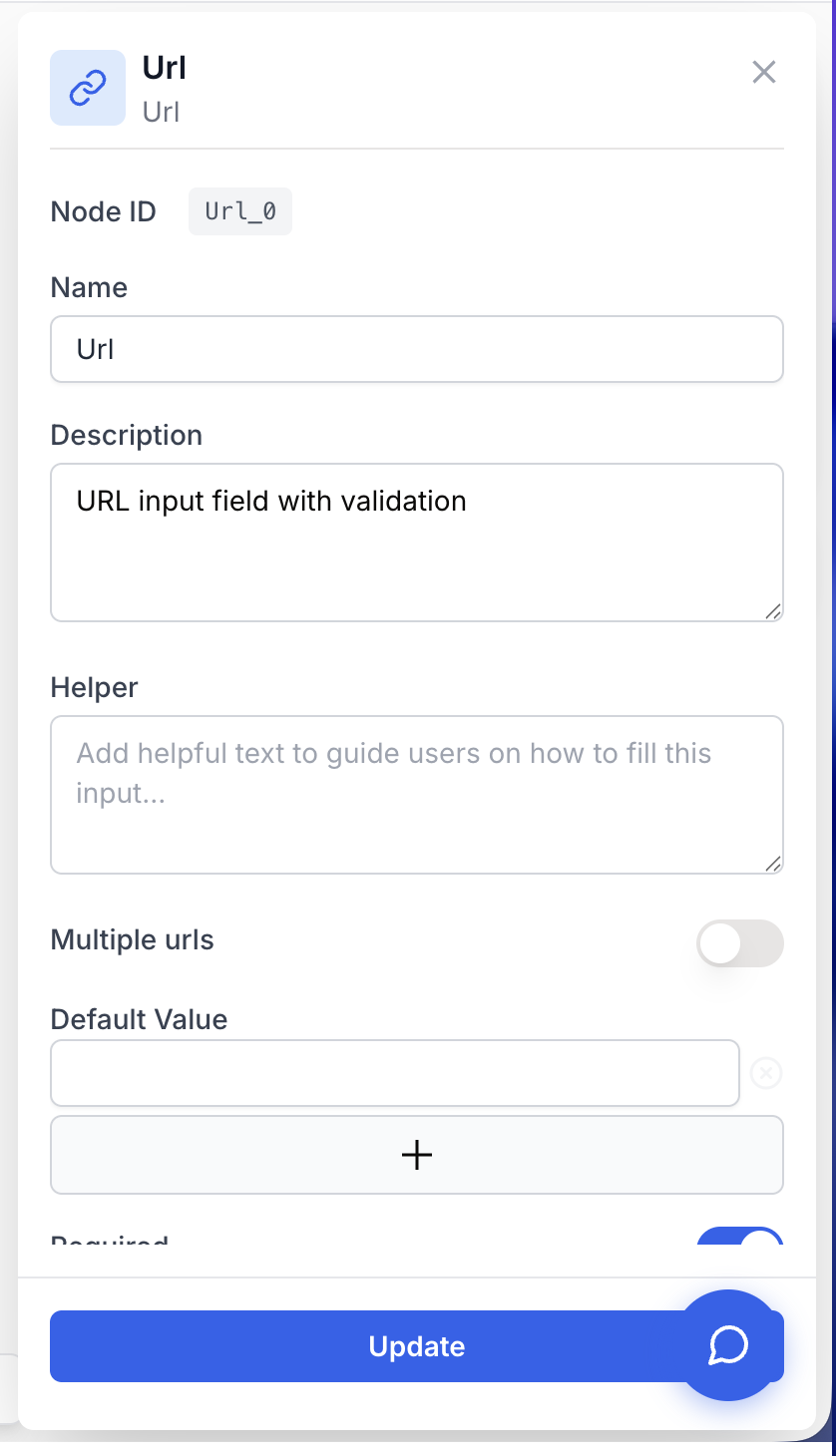
Le node Url ne demande que quelques décisions : mono- vs multi-URL, une valeur pré-remplie optionnelle, et le caractère obligatoire du champ.
Champs requis
Name string required default: Url Nom du node — Utilisé pour référencer la valeur d’URL depuis les autres nodes (par ex. {{Url_0.output}}). Renommez-le en quelque chose de descriptif comme Target_Page lorsque plusieurs entrées URL coexistent dans le même workflow.
Description string required default: A input to receive url(s) to launch the workflow Description du node — Texte court affiché dans l’en-tête du node pour rappeler aux opérateurs quelle URL est attendue (ex. « Page de destination à auditer »).
Multiple urls boolean required default: false Mode multi-URL — Lorsqu’il est activé, le champ accepte une liste d’URL et la sortie devient un tableau de chaînes. Désactivé, le node accepte une seule URL et renvoie une chaîne simple.
Required boolean required default: true Champ obligatoire — Lorsqu’il est activé, le workflow refuse de démarrer tant que l’utilisateur n’a pas fourni d’URL. Désactivez-le uniquement si la suite du graphe gère une entrée vide.
Champs optionnels
Default Value array default: [""] Valeur(s) pré-remplie(s) — URL par défaut affichées dans le champ à l’exécution. Fournissez une seule entrée en mode mono-URL, ou plusieurs entrées lorsque Multiple urls est activé. L’utilisateur final peut toujours les remplacer avant de lancer le workflow.
Renommez le node avant de le câbler. Modifier le Name plus tard vous oblige à mettre à jour manuellement chaque référence {{...}} dans les nodes en aval.
Que renvoie le node ?
Le node expose un unique port de sortie nommé Url. Son type dépend du flag Multiple urls.
output string | string[] La/les URL fournies à l’exécution. Renvoie une simple chaîne lorsque Multiple urls est désactivé, et un tableau de chaînes lorsqu’il est activé.
Comment récupérer l’output ?
- Tirez un lien depuis la sortie du node Url vers l’entrée du node suivant.
- Dans ce node suivant, référencez la valeur avec
{{<NomDuNode>_<index>.output}}— par exemple{{Url_0.output}}pour le premier node Url du canevas. - En mode multi-URL, intercalez un node Loop entre le node Url et le consommateur pour traiter chaque URL indépendamment.
Exemples d’utilisation
Cas 1 : URL unique envoyée à un Web Scraper
Capturer une seule landing page de l’utilisateur, la scraper et nettoyer le HTML.
Configuration :
Name=Target_PageMultiple urls=falseDefault Value=["https://example.com"]Required=true
Sortie (après que l’utilisateur a soumis https://example.com/blog) :
{
"output": "https://example.com/blog"
}graph LR
Url[Url: Target_Page] --> Scraper[Web Scraper]
Scraper --> Cleaner[HTML Cleaner]
Cleaner --> LLM[LLM]Cas 2 : Plusieurs URL traitées via un Loop
Auditer une liste de pages en parallèle.
Configuration :
Name=UrlMultiple urls=trueDefault Value=["https://site.com/a", "https://site.com/b"]Required=true
Sortie :
{
"output": [
"https://site.com/a",
"https://site.com/b"
]
}graph LR
Url[Url: URL List] --> Loop[Loop]
Loop --> Scraper[Web Scraper]
Scraper --> Extractor[JSON Path Extractor]
Extractor --> Output[Final Aggregation]Problèmes courants
Le workflow refuse de démarrer avec `Url is required`
Cause : Le flag Required est activé et aucune URL n’a été fournie au lancement (valeur par défaut vide et soumission utilisateur vide).
Solution : Soit renseigner le champ avant l’exécution, soit définir une Default Value non vide, soit désactiver Required si la suite du graphe tolère une entrée vide.
Le node aval reçoit un tableau alors qu'il attend une chaîne (ou inversement)
Cause : Multiple urls est positionné de manière incohérente avec ce qu’attend le node suivant. En mode multi-URL, output est un tableau ; sinon, output est une simple chaîne.
Solution : Soit aligner Multiple urls avec le type attendu par le consommateur, soit insérer un node Loop pour itérer sur le tableau, soit un node Pick List Item pour en extraire une URL unique.
Une référence du type `{{Url_0.output}}` reste vide dans le node suivant
Cause : Le node Url a été renommé après l’écriture de la référence, ou l’index _0 ne correspond pas à la position réelle du node.
Solution : Rouvrez le node consommateur, supprimez la référence obsolète et re-sélectionnez la sortie du node Url depuis le sélecteur de variables pour que le nom et l’index soient régénérés.
Bonnes pratiques et pièges à éviter
Utilisez Default Value pour livrer un exemple d’URL fonctionnel avec le template du workflow. Les nouveaux utilisateurs peuvent l’exécuter immédiatement pour valider le pipeline avant de substituer leur propre URL.
Ne désactivez pas Required à la légère. Sans cette option, une URL vide se propagera silencieusement jusqu’au Web Scraper ou à l’API Connector, où elle échouera avec une erreur 4xx cryptique loin de la cause réelle.
Nodes complémentaires
Consommateur le plus courant d’un node Url — récupère et parse la page à l’adresse fournie.
Utilise une entrée Url pour cibler des requêtes HTTP arbitraires vers des endpoints fournis par l’utilisateur.
À combiner avec le mode multi-URL pour traiter chaque URL via le même sous-graphe en aval.
À utiliser lorsque l’utilisateur doit fournir du texte libre plutôt qu’une URL.