Data Analyzer
Le node Data Analyzer analyse des fichiers CSV, XLSX, JSON ou XML avec un modèle d'IA à partir d'instructions en langage naturel.
À quoi sert le node Data Analyzer ?
Le node Data Analyzer permet de poser des questions en langage naturel sur un jeu de données structuré (CSV, XLSX, JSON ou XML) et renvoie une réponse générée par une IA. Il transmet le fichier au fournisseur LLM de votre choix afin de résumer, filtrer ou extraire des informations sans écrire de SQL ni de code.
Cas d’usage typiques :
- Résumer de gros jeux de données exportés depuis Google Sheets, BigQuery ou un rapport Haloscan/Semrush.
- Détecter des tendances, anomalies ou valeurs aberrantes (pics de ventes, valeurs manquantes, doublons).
- Répondre à des questions ciblées colonne par colonne (« revenu total par région », « top 10 des clients par montant de commande »).
- Générer des comptes-rendus narratifs courts qu’un node LLM ou WordPress aval pourra publier.
Configuration rapide
Ajouter le node au canevas
Ouvrez la bibliothèque de nodes, allez dans AI puis glissez-déposez le node Data Analyzer sur votre espace de travail. Le node affiche un badge BETA.
Choisir un mode de source de données
Dans le panneau de configuration, choisissez l’un des trois modes Data source :
- Static file — sélectionnez un fichier déjà téléversé dans vos Datasources.
- Dynamic file input — recevez un fichier depuis un node amont via l’ancre d’entrée
Structured File. - Direct data input — recevez des données brutes (string) depuis un node amont via l’ancre d’entrée
Input Data.Sélectionner un modèle
Choisissez un LLM Provider puis un Model name. Seuls les modèles autorisés pour la fonctionnalité Data Analyzer apparaissent.
Rédiger le prompt d’analyse
Modifiez le prompt directement sur le canevas. Utilisez des variables {{nomVariable}} pour injecter des valeurs venant d’un node amont ; chaque variable génère automatiquement une ancre d’entrée correspondante.
Connecter la sortie
Reliez le port Output au node suivant pour exploiter le résultat de l’analyse sous forme de chaîne.
Paramètres de configuration
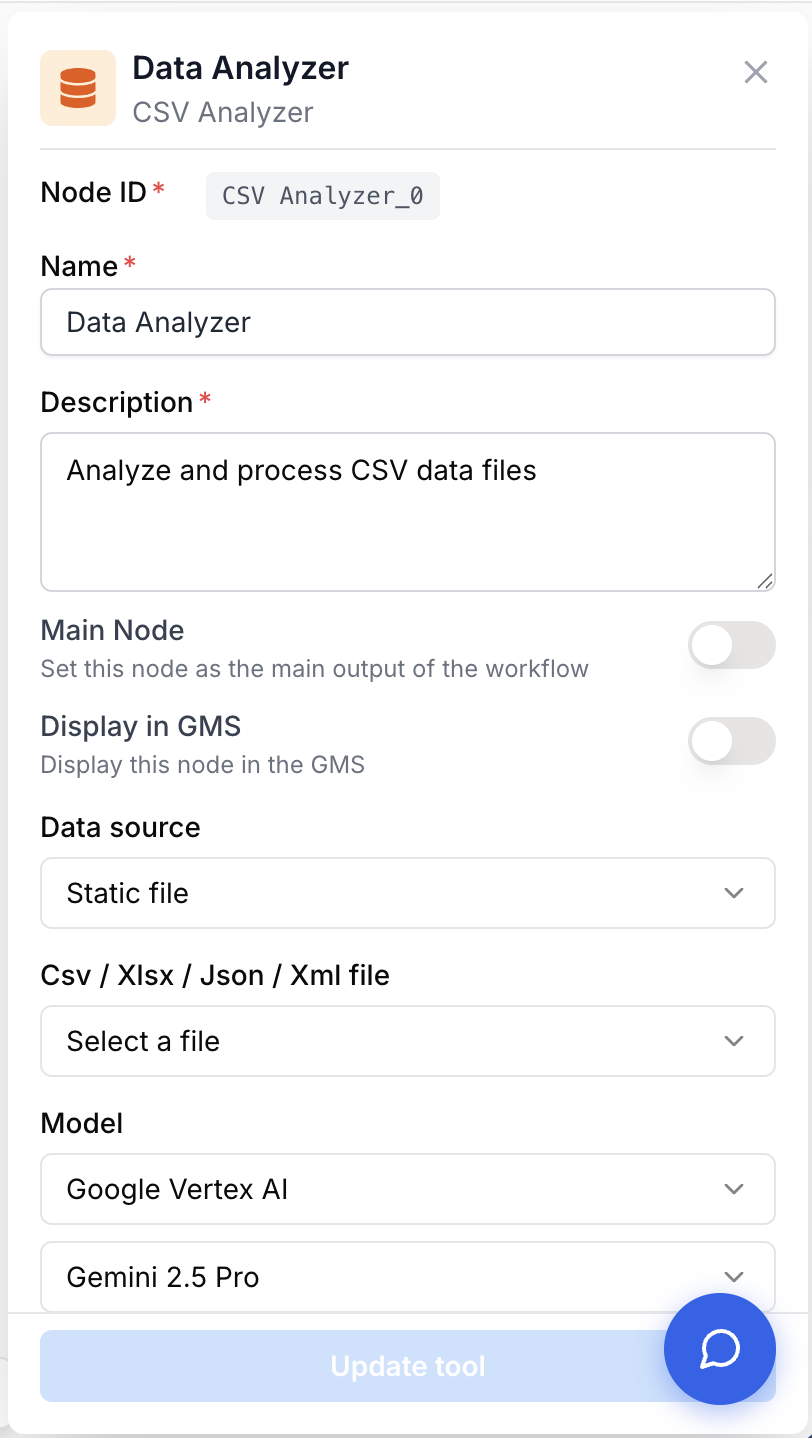
Le node combine un socle commun aux autres nodes IA (Name, Description, Modèle) avec un sélecteur de source de données qui modifie les champs et ancres affichés.
Champs requis
Name string required default: Data Analyzer Nom du node — Sert à identifier le node lors de l’exécution et du débogage du workflow (ex : « Analyse rapport ventes »).
Description string required default: A tool for analyzing csv, xlsx or json file with AI. Description du node — Une courte phrase expliquant le type d’analyse réalisé.
Data Source Mode string required default: static_file Origine du fichier ou des données. Valeurs possibles : static_file, dynamic_file, direct_data. Les autres champs/ancres dépendent de ce choix.
Model name llm required Modèle LLM utilisé pour exécuter l’analyse. Choisissez un modèle autorisé pour la fonctionnalité Data Analyzer dans votre workspace.
prompt string required Instructions d’analyse — Prompt en langage naturel envoyé au modèle avec les données. Supporte les variables dynamiques {{maVariable}} (caractères autorisés : -, _, .). Une erreur est levée si le prompt est vide.
Champs optionnels
File datasource Fichier statique — Requis quand Data Source Mode = static_file. Sélectionnez un fichier déjà téléversé (CSV, XLSX, JSON ou XML) dans vos Datasources. Seuls les fichiers en statut DONE sont sélectionnables.
Structured File file Ancre d’entrée fichier dynamique — Disponible quand Data Source Mode = dynamic_file. Connectez tout node amont qui produit un fichier unique (pas une liste). Le node refuse les entrées de type tableau de fichiers.
Input Data 1 string Ancre d’entrée données directes — Disponible quand Data Source Mode = direct_data. Connectez tout node amont dont la sortie string doit être analysée directement (par exemple un Web Scraper ou un bloc LLM renvoyant un texte de type CSV).
Modifiez le prompt directement sur le canevas pour itérer rapidement, sans rouvrir le panneau de configuration. Les variables saisies en {{nom}} créent automatiquement de nouvelles ancres d’entrée.
Que renvoie le node ?
Le node retourne la réponse textuelle du modèle sous forme d’une chaîne unique sur le port Output. La forme exacte dépend de ce que demande votre prompt : un paragraphe, un tableau Markdown, un blob JSON, une liste, etc.
output string Réponse générée par le modèle à partir du fichier/des données et du prompt. Connectez-la à n’importe quel node qui consomme une string (LLM, Find and Replace, JSON Path Extractor, WordPress Post Create, etc.).
Exemples d’utilisation
Cas 1 : Résumé de ventes depuis un CSV statique
Téléversez un fichier sales_2024.csv dans les Datasources, puis configurez le node :
- Data Source Mode :
Static file - File :
sales_2024.csv - Prompt :
Summarize total revenue per region for January 2024. Return a Markdown table
sorted by revenue descending, then a one-sentence highlight.Sortie attendue :
| Region | Revenue |
|--------|---------|
| North | $125,000 |
| East | $112,000 |
| South | $98,000 |
| West | $89,000 |
North led January with 28% of total revenue.Cas 2 : Détection d’anomalies sur un fichier dynamique
Un node Google Drive récupère le dernier export, puis le transmet au Data Analyzer.
- Data Source Mode :
Dynamic file input - Connectez Google Drive → Data Analyzer (ancre
Structured File). - Prompt :
Inspect the dataset for data-quality issues. List rows with missing values,
negative numbers, or duplicates. Format the answer as a bulleted list.Cas 3 : Données directes avec une variable de prompt
Exécutez un Web Scraper, passez sa sortie brute en données directes et utilisez une variable pour cadrer la question.
- Data Source Mode :
Direct data input - Connectez Web Scraper → Data Analyzer (ancre
Input Data 1). - Prompt :
From the data below, extract the top {{topN}} products by sold_units.
Return JSON: [{"product": "...", "sold_units": ...}].En reliant un Text Input à l’ancre topN générée automatiquement, vous changez le seuil sans modifier le prompt.
Problèmes courants
Le node refuse ma connexion sur l'ancre Structured File
Cause : Le node amont produit une liste de fichiers, ou sa sortie n’est pas de type file. Le Data Analyzer n’accepte qu’un seul fichier.
Solution : Intercalez un node Pick List Item pour extraire un fichier de la liste, ou basculez sur Direct data input si la sortie amont est une string.
Erreur de validation : « requires instructions to be configured »
Cause : Le champ prompt est vide ou ne contient que des espaces.
Solution : Ouvrez le node sur le canevas et saisissez vos instructions d’analyse dans la zone prompt avant d’exécuter le workflow.
Le sélecteur « Static file » est vide ou affiche un bandeau jaune
Cause : Aucun fichier en statut DONE n’est téléversé pour votre workspace, ou votre fichier est encore en cours de traitement.
Solution : Cliquez sur Upload a file dans le bandeau pour ajouter un fichier CSV/XLSX/JSON/XML, puis attendez qu’il passe en statut DONE avant de le sélectionner.
Mes variables de prompt n'apparaissent pas comme ancres d'entrée
Cause : Les variables utilisent des caractères interdits ou n’ont pas été enregistrées.
Solution : Utilisez uniquement des lettres, chiffres, -, _, et . à l’intérieur de {{...}}. Sauvegardez le prompt ; les ancres d’entrée correspondantes sont générées automatiquement.
Bonnes pratiques
Soyez précis sur les noms de colonnes et le format de sortie attendu. « Return revenue by region as a Markdown table sorted descending » donnera de meilleurs résultats que « tell me about the data » et consommera moins de tokens.
Les fichiers volumineux (dizaines de milliers de lignes) peuvent dépasser la fenêtre de contexte du modèle. Pré-agrégez avec BigQuery Reader ou filtrez avec une requête Google Sheets avant d’envoyer le résultat au Data Analyzer.
Comment s’intègre-t-il dans un workflow ?
Le Data Analyzer s’utilise généralement comme étape de « lecture + raisonnement » entre une étape de collecte de données et une étape de publication ou d’aiguillage :
graph LR
DS[Google Drive / BigQuery / Web Scraper] --> CSV[Data Analyzer]
CSV --> CL[Find and Replace
<br/>nettoie la sortie]
CL --> EX[JSON Path Extractor]
EX --> WP[WordPress Post Create]Nodes complémentaires
Exécutez un prompt libre sans contexte fichier, ou post-traitez la sortie du Data Analyzer.
Combinez plusieurs outils (dont Data Analyzer) à l’intérieur d’un agent autonome.
Extrayez des champs structurés depuis une réponse JSON produite par le Data Analyzer.
Supprimez les délimiteurs Markdown ou caractères parasites de la sortie modèle avant un parsing aval.