Google BigQuery Reader
Le node Google BigQuery Reader exécute des requêtes SQL sur Google BigQuery et renvoie les résultats sous forme de données structurées pour les nodes en aval.
À quoi sert le node Google BigQuery Reader ?
Le node Google BigQuery Reader se connecte à votre projet Google Cloud et exécute une requête SQL sur BigQuery, puis renvoie les lignes sous forme de chaîne JSON. Il vous permet de récupérer de gros jeux de données analytiques, des tables d’entrepôt ou des résultats agrégés directement dans votre workflow, sans export manuel ni fichier intermédiaire.
Cas d’usage typiques :
- Extraire les performances quotidiennes des campagnes depuis un entrepôt marketing pour les résumer avec un LLM
- Récupérer les lignes d’un catalogue produit pour les enrichir, classer ou générer du contenu en aval
- Exécuter une requête d’agrégation (par exemple le revenu par canal) et alimenter un node de reporting
- Joindre des tables BigQuery à la volée pour bâtir un jeu de données qu’un autre node consomme ligne par ligne
Configuration rapide
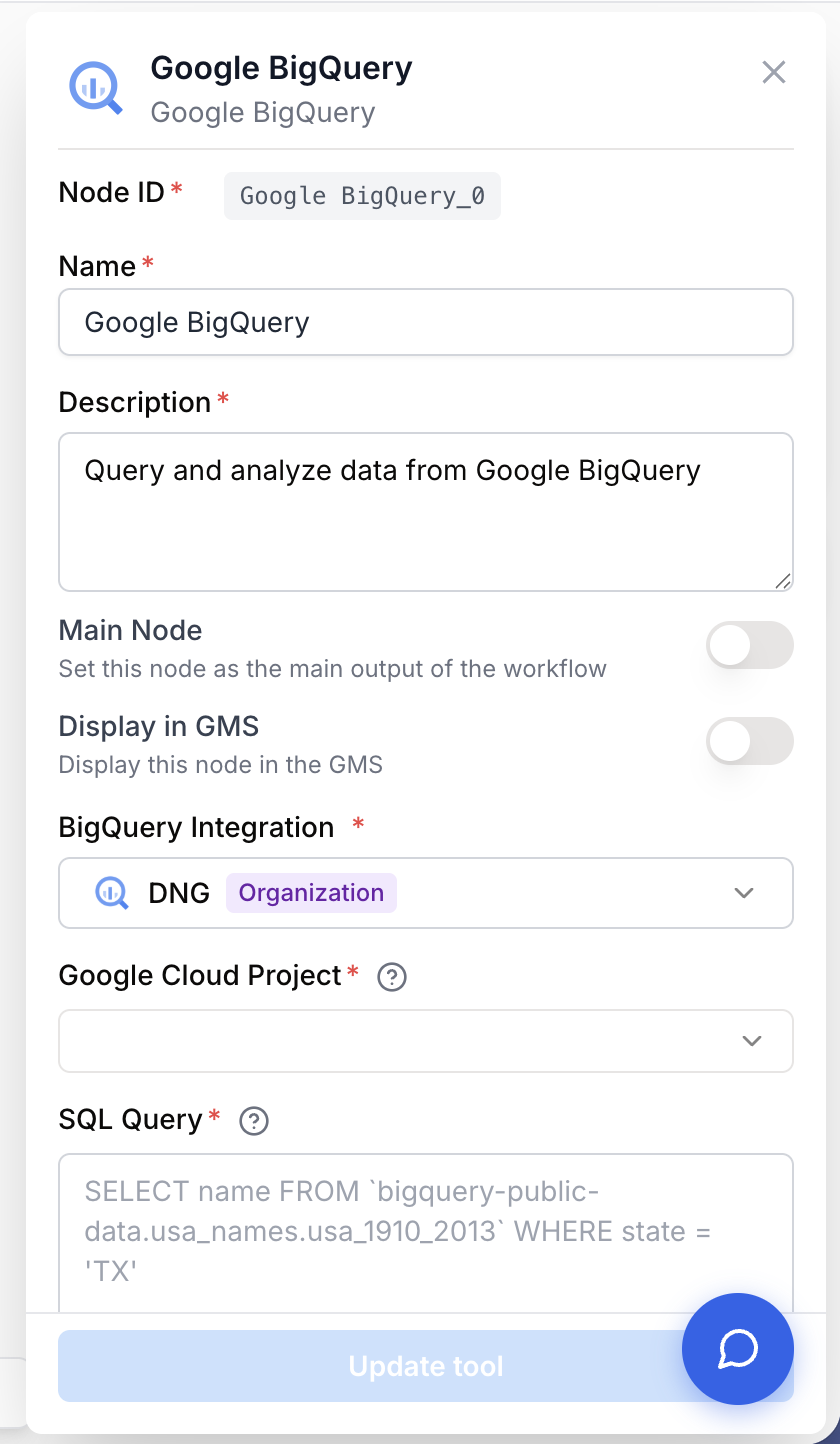
Connectez une intégration BigQuery
Ouvrez les paramètres du node et choisissez une BigQuery Integration dans la liste déroulante. Si aucune n’est disponible, allez dans Settings > Integrations pour connecter un compte Google avec un accès BigQuery.
Sélectionnez le projet Google Cloud
Une fois l’intégration connectée, choisissez le Google Cloud Project qui contient votre dataset. La liste déroulante est alimentée automatiquement avec les projets visibles par l’intégration.
Rédigez la requête SQL
Dans le champ SQL Query, saisissez une requête SELECT valide en BigQuery Standard SQL. Référencez les tables qualifiées entre backticks, par exemple `bigquery-public-data.usa_names.usa_1910_2013`.
Connectez la sortie
Connectez le port de sortie au node suivant. Les résultats sont émis sous forme de chaîne JSON, prêts à alimenter un Loop, un JSON Path Extractor, un LLM ou tout autre node en aval.
Paramètres de configuration
Champs obligatoires
integration_id integration required BigQuery Integration — Sélectionnez la connexion au compte Google à utiliser. L’intégration doit disposer d’un accès en lecture à BigQuery sur le projet cible.
google_cloud_project string required Google Cloud Project — Le projet Google Cloud qui héberge votre dataset BigQuery. Sélectionnez-le dans la liste alimentée par l’intégration choisie. Changer d’intégration réinitialise ce champ.
sql_query string required SQL Query — La requête BigQuery Standard SQL à exécuter. Utilisez des backticks autour des noms de tables qualifiés et les fonctions BigQuery standard. Les variables de template comme {{start_date}} sont résolues à l’exécution depuis les sorties des nodes en amont.
SELECT name, state, number
FROM `bigquery-public-data.usa_names.usa_1910_2013`
WHERE state = 'TX'
LIMIT 100Vous pouvez injecter des variables de template partout dans la requête (par exemple WHERE date >= '{{start_date}}'). Elles sont résolues depuis les entrées en amont avant l’envoi à BigQuery.
Que produit le node en sortie ?
Le node produit les résultats sous forme d’une chaîne JSON unique contenant le tableau des lignes. Chaque ligne est un objet dont les clés correspondent aux noms de colonnes renvoyés par la requête.
[
{ "name": "Maria", "state": "TX", "number": 12345 },
{ "name": "James", "state": "TX", "number": 11200 }
]columnsoutput string Une chaîne JSON contenant le tableau des lignes renvoyées par la requête. L’ordre et les noms des colonnes correspondent à la clause SELECT.
Exemples d’utilisation
Exemple 1 : Rapport de revenu quotidien
Vous souhaitez résumer le revenu par campagne de la semaine passée et alimenter un LLM pour produire un compte-rendu.
Configuration :
- BigQuery Integration : Marketing GCP
- Google Cloud Project :
acme-marketing-prod - SQL Query :
SELECT date, campaign, SUM(revenue) AS total FROM `acme-marketing-prod.ads.campaign_revenue` WHERE date >= DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) GROUP BY date, campaign ORDER BY date
Connectez la sortie à un node LLM avec une consigne du type Résume les tendances de revenu hebdomadaire à partir du JSON ci-dessous.
Exemple 2 : Boucler sur les lignes pour un traitement unitaire
Vous devez enrichir chaque produit d’un catalogue avec une description générée.
Configuration :
- SQL Query :
SELECT sku, title, category FROM `acme-prod.catalog.products` WHERE active = TRUE
Branchez la sortie sur un node Loop, puis un node LLM qui rédige une description par ligne.
Exemple 3 : Plage de dates dynamique avec des variables de template
Réutilisez le même node entre workflows en paramétrant le filtre de date.
Configuration :
- SQL Query :
SELECT user_id, event, ts FROM `acme-prod.analytics.events` WHERE DATE(ts) BETWEEN '{{start_date}}' AND '{{end_date}}'
Les valeurs start_date et end_date proviennent de nodes Date ou Text Input en amont.
Problèmes courants
Le node échoue avec BigQuery integration is not configured
Cause : Aucune intégration BigQuery n’est sélectionnée sur le node.
Solution : Ouvrez les paramètres du node et choisissez une intégration BigQuery dans la liste. Si aucune n’apparaît, ajoutez-en une dans Settings > Integrations.
L'identifiant du projet Google Cloud est manquant
Cause : Le champ Google Cloud Project est vide, souvent parce que l’intégration vient d’être changée et que le projet précédent a été réinitialisé.
Solution : Sélectionnez un projet dans la liste après le chargement de l’intégration. La liste est rafraîchie automatiquement quand vous changez d’intégration.
La requête SQL est vide ou rejetée par BigQuery
Cause : Le champ SQL Query est vide, ne contient que des espaces, ou la syntaxe n’est pas du BigQuery Standard SQL valide.
Solution : Testez d’abord la requête dans la console BigQuery. Utilisez bien des backticks autour des tables qualifiées (project.dataset.table) et des fonctions Standard SQL.
Permission refusée ou table introuvable
Cause : Le compte de l’intégration n’a pas l’accès en lecture au dataset, ou la référence de table est incorrecte.
Solution : Vérifiez que le compte de service ou utilisateur dispose au moins des rôles BigQuery Data Viewer et BigQuery Job User sur le projet cible. Revérifiez les noms de dataset et de table.
Les requêtes expirent ou renvoient trop de données
Cause : La requête scanne des tables volumineuses sans filtre ou renvoie des millions de lignes qui saturent les nodes en aval.
Solution : Ajoutez une clause WHERE sur une colonne partitionnée, utilisez LIMIT, ou pré-agrégez avec GROUP BY. Évitez SELECT * sur les grosses tables.
Bonnes pratiques
Filtrez sur les colonnes partitionnées. La plupart des tables analytiques BigQuery sont partitionnées par date. Ajouter WHERE date >= ... réduit drastiquement les octets scannés et le coût.
Ne sélectionnez que les colonnes nécessaires. Lister explicitement les colonnes est plus rapide, moins coûteux et plus robuste aux changements de schéma que SELECT *.
Évitez les requêtes non bornées. Une requête qui scanne des téraoctets peut atteindre les quotas du projet, ralentir votre workflow et générer des coûts inattendus. Prévisualisez toujours les octets traités dans la console BigQuery.
Assainissez les variables de template. Les valeurs injectées via {{var}} ne sont pas paramétrées côté BigQuery. Assurez-vous que les valeurs en amont proviennent de sources fiables avant de les utiliser dans les clauses WHERE.
Comment s’intègre-t-il dans un workflow ?
Le Google BigQuery Reader est généralement utilisé en début de workflow pour récupérer un jeu de données que les nodes suivants traitent ligne par ligne ou de manière agrégée.
graph LR
BQ[Google BigQuery Reader] --> Loop[Loop node]
Loop --> LLM[Le node LLM traite chaque ligne]
LLM --> Out[Écriture des résultats en aval]Nodes associés
Itérez sur chaque ligne renvoyée par la requête pour les traiter individuellement.
Extrayez des champs spécifiques de la sortie BigQuery lorsque vous n’avez besoin que de certaines colonnes.
Utilisez un modèle d’IA pour résumer, analyser ou transformer les lignes récupérées depuis BigQuery.
Écrivez des lignes dans BigQuery après enrichissement ou transformation.