Google Docs Reader
Le node Google Docs Reader récupère le contenu et les métadonnées d'un ou plusieurs documents Google Docs, avec sélection multi-documents, contrôle des onglets par document et trois formats de sortie.
À quoi sert le node Google Docs Reader ?
Le node Google Docs Reader se connecte à votre compte Google et lit le contenu et les métadonnées d’un ou plusieurs documents Google Docs. Il prend en charge la sélection multi-documents via Google Drive Picker, la sélection d’onglets par document et trois formats de sortie (JSON, plain text, Markdown).
Cas d’usage typiques :
- Récupérer plusieurs rapports marketing pour une synthèse assistée par IA
- Lire des briefs SEO ou des articles pour alimenter un pipeline d’analyse LLM
- Extraire de la documentation technique pour des workflows de traduction automatisée
- Récupérer le contenu d’onglets sélectionnés de documents volumineux pour limiter la consommation de tokens
Configuration rapide
Connectez votre intégration Google
Ouvrez les paramètres du node et sélectionnez votre intégration Google Docs dans la liste déroulante. Si Google n’est pas encore connecté, allez dans Settings > Integrations et authentifiez-vous avec le scope google_docs.
Sélectionnez les documents
Cliquez sur le Google Drive Picker pour parcourir votre Drive et sélectionner un ou plusieurs documents. Le Picker remplit automatiquement document_ids et document_names.
Choisissez un format de sortie
Réglez Output Type sur markdown (recommandé pour les LLM), plain_text ou json selon ce que le node suivant attend.
Configurez la sélection d’onglets (optionnel)
Laissez Read All Tabs activé pour lire tous les onglets, ou désactivez-le et choisissez des onglets spécifiques par document via la fenêtre de sélection. Utile pour les documents volumineux.
Connectez la sortie
Reliez la sortie document_data au node suivant — typiquement un Loop, un LLM ou un JSON Path Extractor.
Paramètres de configuration
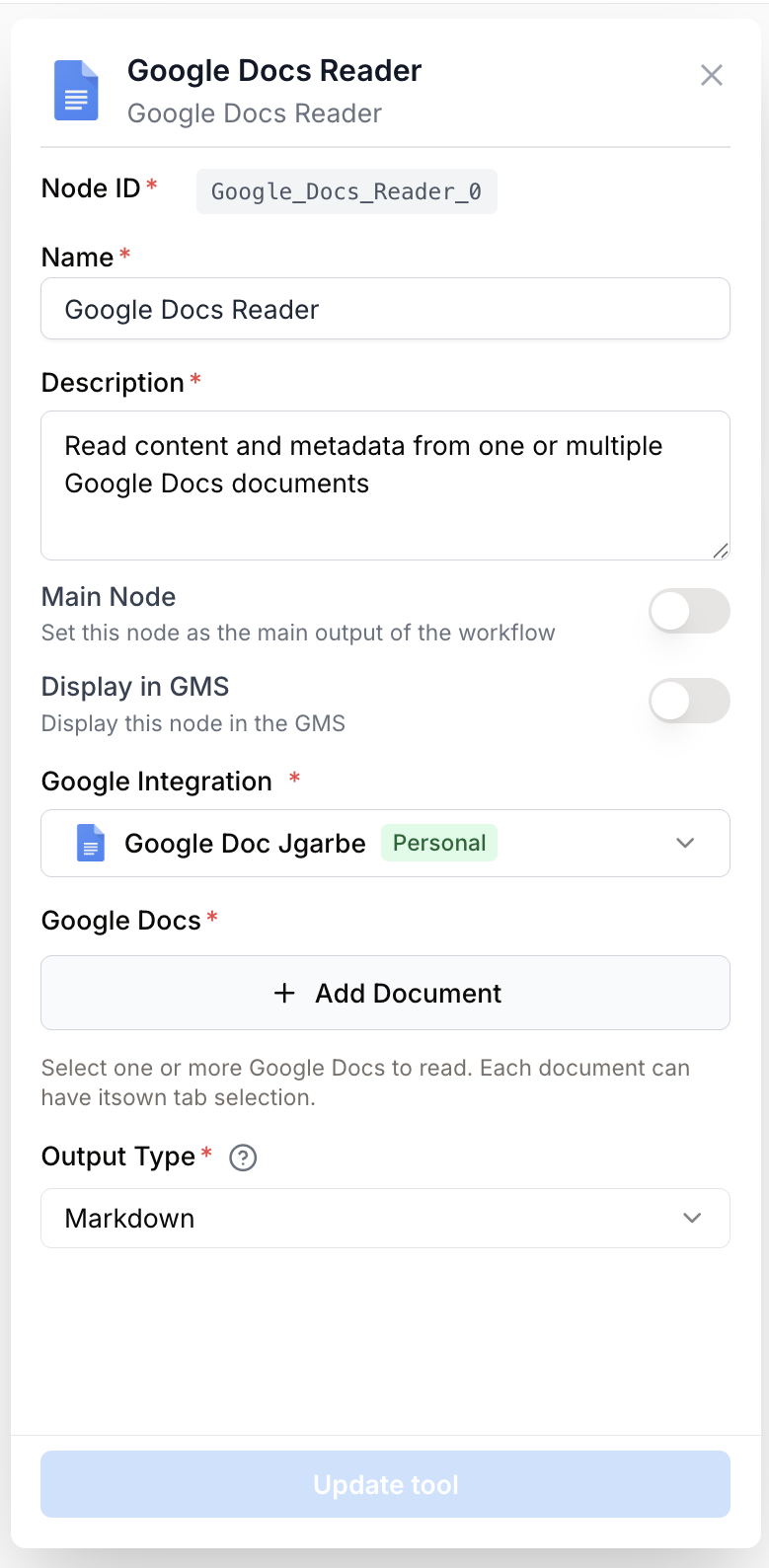
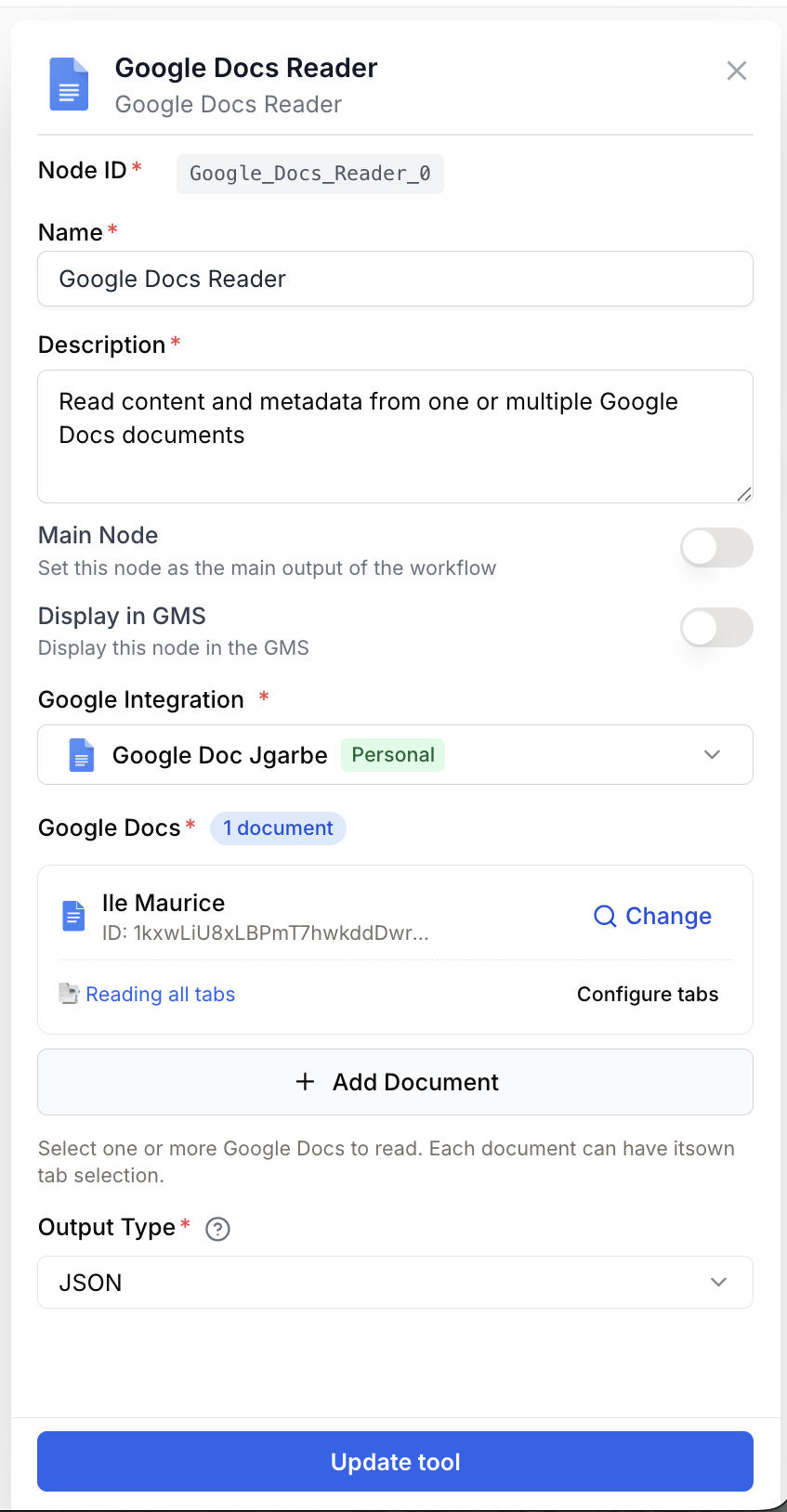
Champs obligatoires
integration_id integration required Intégration Google Docs — Sélectionnez la connexion Google à utiliser. L’intégration doit être authentifiée avec le scope google_docs et disposer d’un accès en lecture aux documents.
document_ids string[] required Identifiants des documents — Liste des IDs des documents Google Docs à lire. Utilisez le Google Drive Picker intégré pour sélectionner un ou plusieurs documents. Accepte un tableau ou une chaîne séparée par des virgules pour la rétrocompatibilité.
Champs optionnels
document_names string[] Noms des documents — Noms d’affichage des documents sélectionnés. Rempli automatiquement par le Picker. Utilisé dans la charge utile de sortie pour la lisibilité.
output_type select default: markdown Format de sortie — Format du contenu extrait.
| Valeur | Description |
|---|---|
json | JSON structuré avec les métadonnées complètes du document |
plain_text | Texte brut sans formatage |
markdown | Contenu au format Markdown (recommandé pour le traitement LLM) |
read_all_tabs boolean default: true Lire tous les onglets — Lorsqu’il est activé, chaque onglet de chaque document est lu. Désactivez-le pour sélectionner des onglets spécifiques par document.
selected_tabs object default: {} Onglets sélectionnés — Sélection d’onglets par document. Lorsque read_all_tabs est désactivé, utilisez la fenêtre de sélection pour choisir les onglets à lire pour chaque document. Stocké sous forme de map JSON associant les IDs de documents aux métadonnées des onglets.
Utilisez la sortie Markdown pour les nodes LLM en aval — elle préserve les titres, listes et liens tout en restant compacte et facile à interpréter pour le modèle.
Que produit le node en sortie ?
Le node renvoie une seule sortie contenant le contenu et les métadonnées de tous les documents sélectionnés.
document_data string Chaîne JSON contenant un tableau de documents. Chaque entrée inclut document_id, title, url et un tableau tabs avec tab_id, tab_name et content formaté selon output_type.
Exemple de charge utile :
{
"documents": [
{
"document_id": "1aBcDeFgHiJkLmNoPqRsTuVwXyZ",
"title": "Rapport Marketing Q1",
"tabs": [
{
"tab_id": "t.0",
"tab_name": "Vue d'ensemble",
"content": "# Rapport Marketing Q1\n\nCe trimestre a connu une augmentation de 25%..."
}
],
"url": "https://docs.google.com/document/d/1aBcDeFgHiJkLmNoPqRsTuVwXyZ"
}
]
}Référencez la sortie en aval avec {{Google_Docs_Reader_0.document_data}}.
Exemples d’utilisation
Exemple 1 : Synthétiser plusieurs rapports avec un LLM
Vous avez plusieurs rapports marketing trimestriels dans Google Docs et souhaitez recevoir une synthèse exécutive par email.
Configuration :
- Intégration : Google Docs
- Document IDs : 3 à 5 rapports sélectionnés via le Picker
- Output Type :
markdown - Read All Tabs : Activé
Branchez document_data sur un LLM avec le prompt : Résume chaque document en 3 points clés. Envoyez le résultat via un node Email Sender.
graph LR
A[Google Docs Reader] --> B[LLM]
B --> C[Email Sender]Exemple 2 : Traduire les onglets sélectionnés d’un set de documentation
Vous maintenez un fichier de documentation multi-onglets et souhaitez traduire uniquement les onglets destinés aux utilisateurs.
Configuration :
- Document IDs : le fichier de documentation
- Output Type :
markdown - Read All Tabs : Désactivé
- Selected Tabs : uniquement les onglets publics
Reliez la sortie à un LLM traducteur et écrivez le résultat avec un node Google Docs Writer.
Exemple 3 : Extraction programmatique de métadonnées
Utilisez Output Type json pour accéder aux champs de métadonnées bruts. Branchez la sortie sur un JSON Path Extractor pour extraire les tableaux title et url à des fins d’indexation.
Problèmes courants
Aucun contenu retourné pour un document
Cause : L’intégration Google n’a pas d’accès en lecture, ou le scope google_docs est manquant.
Solution : Allez dans Settings > Integrations, reconnectez l’intégration Google avec le scope google_docs et vérifiez que le compte authentifié a accès au document.
Le contenu des onglets est manquant ou incomplet
Cause : read_all_tabs est désactivé et les onglets pertinents ne sont pas sélectionnés, ou certains onglets exigent des permissions supplémentaires.
Solution : Activez read_all_tabs pour confirmer que le contenu est accessible. Si vous ne voulez qu’un sous-ensemble, ouvrez la fenêtre de sélection et vérifiez les bons onglets pour chaque document.
Erreur : Missing required parameter document_ids
Cause : Aucun document n’a été sélectionné, ou la variable en amont alimentant document_ids est vide.
Solution : Rouvrez le Picker et sélectionnez au moins un document, ou vérifiez que le node en amont produit un tableau ou une chaîne séparée par des virgules non vide.
Erreur : Missing Google Docs Integration
Cause : Le paramètre integration_id est vide.
Solution : Sélectionnez une intégration Google Docs dans les paramètres du node. Créez-en une dans Settings > Integrations si nécessaire.
Bonnes pratiques
Utilisez la sortie Markdown pour les nodes LLM. Elle préserve la structure du document (titres, listes, liens) tout en restant compacte et facile à interpréter pour le modèle.
Limitez la lecture des onglets sur les gros documents. Désactivez read_all_tabs et choisissez uniquement les onglets nécessaires — moins de tokens, exécutions plus rapides, coût plus faible.
Partagez les documents avec le compte authentifié. Les documents non partagés avec le compte Google de l’intégration peuvent retourner un contenu vide sans erreur dans certains cas.
Attention aux limites de contexte des LLM. Lire de nombreux documents en une fois peut dépasser la fenêtre de contexte du modèle. Utilisez un node Loop pour traiter les documents un à un si nécessaire.
Nodes associés
Créez ou mettez à jour des documents Google Docs avec le contenu produit en aval.
Synthétisez, traduisez ou analysez le contenu récupéré depuis Google Docs.
Itérez sur chaque document ou onglet pour les traiter un à un.
Extrayez des champs spécifiques de la charge utile JSON (titres, URLs, contenu d’onglets).