Internal Link Recommendation
Le node Internal Link Recommendation classe les pages d'un dataset CSV en croisant similarité sémantique et PageRank pour faire émerger les meilleures opportunités de maillage interne.
À quoi sert le node Internal Link Recommendation ?
Le node Internal Link Recommendation prend une requête textuelle et classe les pages d’un dataset CSV en combinant deux signaux : la similarité sémantique entre la requête et chaque titre de page (TF-IDF + cosinus, avec stopwords adaptés à la langue détectée) et le score PageRank interne de la page (colonne inrank). Il renvoie le top N sous forme de tableau JSON, avec une rotation aléatoire entre les pages sélectionnées pour éviter de toujours proposer exactement les mêmes suggestions.
Cas d’usage typiques :
- Générer une short-list de liens internes pertinents lors de la rédaction d’un article.
- Construire des cocons sémantiques en faisant ressortir les pages thématiquement liées à un sujet pilier.
- Mieux distribuer le link equity en augmentant le poids du PageRank pour favoriser les pages à forte autorité.
Configuration rapide
Ajouter le node au canevas
Ouvrez la bibliothèque de nodes (Node Library), allez dans Integrations > SEO Tools, puis glissez-déposez le node Internal Link Recommendation sur votre espace de travail.
Préparer le dataset d’URLs
Exportez un CSV depuis votre crawler (Screaming Frog, Oncrawl, etc.) contenant exactement trois colonnes en minuscules : url, title et inrank. La colonne inrank doit être numérique.
Configurer le node
Uploadez le CSV dans URL Dataset, définissez Number of links to return puis ajustez Semantic Weight et PageRank Weight selon votre stratégie de maillage.
Connecter les entrées et la sortie
Reliez une source texte (LLM, Text Input, Paragraph) à l’entrée Query, puis branchez la sortie au node suivant (LLM pour formater des ancres HTML, Find and Replace pour injecter dans un template, etc.).
Paramètres de configuration
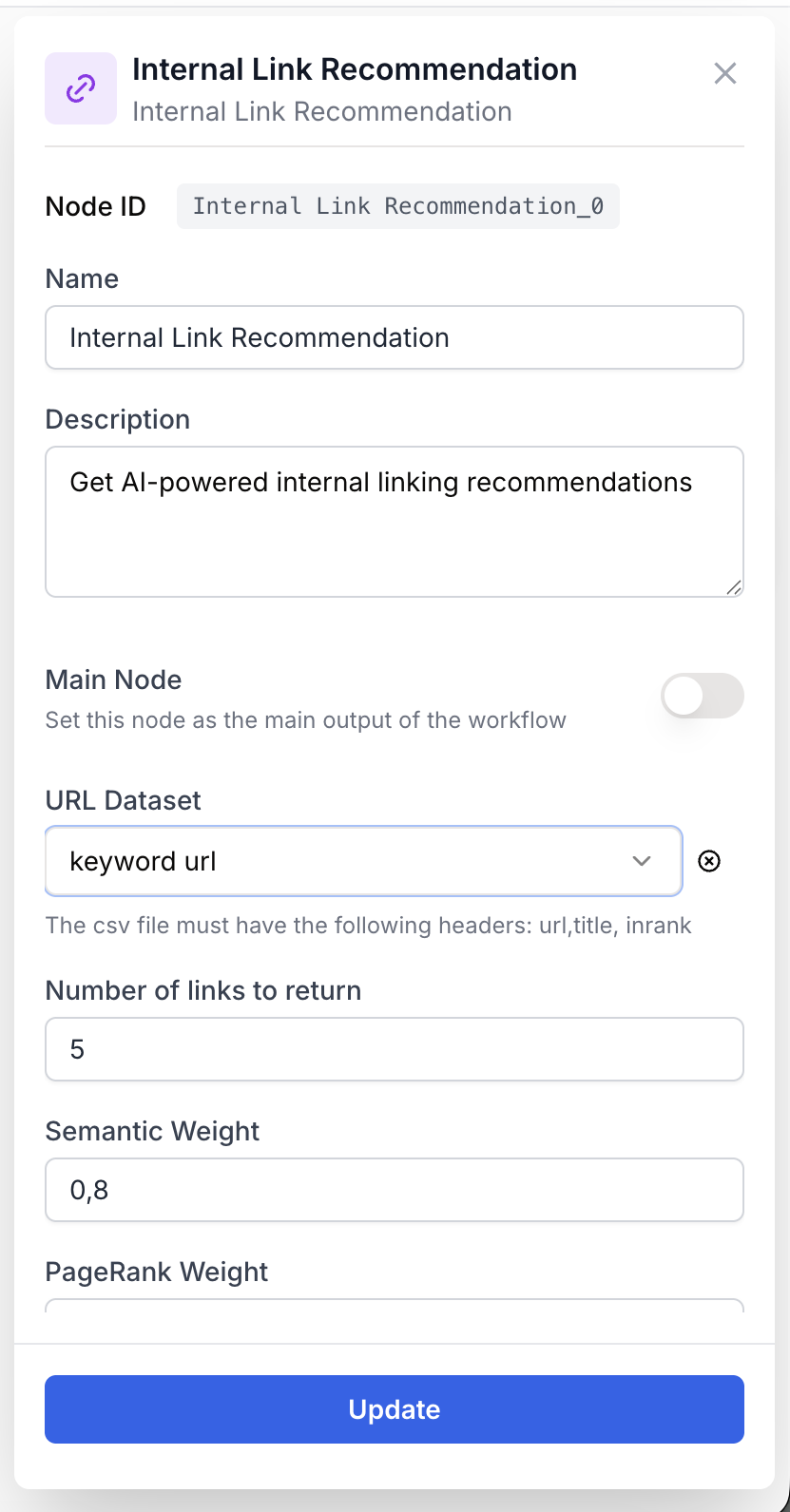
Le node combine un port d’entrée pour la requête et des paramètres dans le panneau latéral.
Champs requis
Name string required default: Internal Link Recommendation Nom du node — Sert à identifier le node lors de l’exécution et du débogage du workflow (ex : Maillage blog).
Description string required default: Recommends internal links based on content relevance and page importance Description du node — Courte phrase décrivant ce que fait cette instance du node.
Query string required Port d’entrée — Le texte utilisé pour scorer les pages. Typiquement un ensemble de mots-clés, un titre d’article ou un paragraphe du contenu en cours de rédaction. Une requête vide déclenche Internal Link Recommendation Tool: Missing query parameter.
URL Dataset csv required Un fichier CSV (ou XLSX) uploadé en tant que Datasource. Colonnes requises (insensibles à la casse, mises en minuscules à la lecture) :
url— URL absolue de la page.title— Titre de la page utilisé pour l’appariement sémantique.inrank— Score PageRank interne (numérique).
Le délimiteur CSV est auto-détecté (,, ;, tab ou |). L’encodage est auto-détecté via chardet. Les lignes invalides sont ignorées.
Champs optionnels
Number of links to return number default: 5 Nombre de recommandations à retourner. Plage de 1 à 20. Le node peut en retourner moins si peu de pages ont une similarité strictement positive.
Semantic Weight number default: 0.8 Coefficient appliqué au score de similarité cosinus dans le classement final (0 à 1, pas de 0,1). Des valeurs plus élevées privilégient les pages dont les titres collent le mieux à la requête.
PageRank Weight number default: 0.4 Coefficient appliqué au score inrank normalisé (min-max) dans le classement final (0 à 1, pas de 0,1). Des valeurs plus élevées privilégient les pages à forte autorité indépendamment du match sémantique.
Les deux poids sont indépendants et ne doivent pas obligatoirement faire 1 au total. Le score final est semanticWeight * similarity + pageRankWeight * normalizedInrank. Une configuration 0.8 / 0.4 signifie que la pertinence sémantique pèse environ deux fois plus que l’autorité.
Les stopwords sont chargés automatiquement selon la langue détectée à partir des titres (anglais, français, allemand, italien, portugais, espagnol). Si la détection échoue, l’anglais est utilisé par défaut.
Que renvoie le node ?
Le node renvoie une chaîne JSON représentant un tableau de liens recommandés, triés par final_score décroissant puis pivotés selon un offset aléatoire. Les pages dont la similarité vaut 0 sont filtrées. Chaque entrée contient l’URL source, le titre, le inrank brut, la similarité cosinus et le final_score combiné.
Comment récupérer l’output ?
- Tirez un lien depuis la sortie Recommended Links.
- Connectez-le au node suivant (typiquement un LLM, un JSON Path Extractor ou un HTML to Markdown).
- Dans ce node suivant, nommez votre propre variable (par exemple
liens_json). La chaîne JSON y est injectée directement. Passez-la à un JSON Path Extractor ou demandez à un LLM de formater des ancres HTML.
Recommended Links string Tableau JSON encodé en chaîne, dont chaque objet possède les champs url, title, inrank, similarity, final_score. Tableau vide si aucune page n’a une similarité supérieure à 0.
[
{
"url": "https://example.com/guides/technical-seo-checklist",
"title": "Technical SEO Checklist for 2025",
"inrank": 7.8,
"similarity": 0.91,
"final_score": 0.98
},
{
"url": "https://example.com/blog/crawl-budget-optimization",
"title": "How to Optimize Your Crawl Budget",
"inrank": 6.3,
"similarity": 0.84,
"final_score": 0.87
}
]Exemples d’utilisation
Cas 1 : Maillage éditorial depuis un brouillon d’article
Vous rédigez un article sur l’audit SEO technique et voulez cinq liens internes pertinents à intégrer dans le corps du texte.
Donnée d’entrée (Query) :
audit SEO technique erreurs de crawl indexationDataset CSV (extrait) :
url,title,inrank
https://exemple.com/guides/checklist-seo-technique,Checklist SEO technique 2025,7.8
https://exemple.com/blog/optimisation-budget-crawl,Optimiser son budget de crawl,6.3
https://exemple.com/outils/audit-site,Outil d'audit de site gratuit,9.1
https://exemple.com/blog/recettes,Meilleures recettes de pâtes,4.2Configuration :
Number of links to return: 5Semantic Weight: 0.8PageRank Weight: 0.4
Output :
[
{
"url": "https://exemple.com/guides/checklist-seo-technique",
"title": "Checklist SEO technique 2025",
"inrank": 7.8,
"similarity": 0.91,
"final_score": 1.04
},
{
"url": "https://exemple.com/outils/audit-site",
"title": "Outil d'audit de site gratuit",
"inrank": 9.1,
"similarity": 0.42,
"final_score": 0.74
}
]La page de recettes est filtrée car sa similarité vaut 0.
Cas 2 : Construction d’un cocon avec biais d’autorité
Vous bâtissez un cocon sémantique autour de content marketing et souhaitez favoriser les pages à forte autorité.
Configuration :
Number of links to return: 10Semantic Weight: 0.5PageRank Weight: 0.7
Workflow :
graph LR
Input[Text Input
<br/>mots-clés du sujet] --> ILR[Internal Link Recommendation]
ILR --> LLM[LLM
<br/>formate les ancres HTML]
LLM --> FR[Find and Replace
<br/>injecte dans le template]Le LLM consomme le tableau JSON et produit des ancres HTML prêtes à coller. Le Find and Replace remplace ensuite un placeholder du template d’article par le bloc généré.
Problèmes courants
La sortie est un tableau vide
Cause : Aucune page du dataset n’a une similarité TF-IDF non nulle avec la requête (vocabulaire incompatible, titres très courts ou stopwords trop agressifs).
Solution : Élargissez la requête, vérifiez que les titres sont descriptifs, et confirmez que la langue détectée correspond à celle du dataset. Une requête composée uniquement de stopwords produit également des similarités nulles.
Le node échoue avec `Title column not found`, `Url column not found` ou `Inrank column not found`
Cause : L’en-tête du CSV ne contient pas l’une des colonnes obligatoires. Les en-têtes sont mis en minuscules à la lecture, mais la colonne doit être présente.
Solution : Réexportez le CSV avec exactement url, title, inrank (la casse n’importe pas, mais les noms doivent matcher).
Le node échoue avec `Page rank must be a number`
Cause : La colonne inrank contient des valeurs non numériques (texte, cellules vides, séparateurs de milliers).
Solution : Nettoyez la colonne avant export. Les valeurs doivent être numériques (entiers ou décimaux). Supprimez ou complétez les lignes sans PageRank.
Les suggestions changent d'une exécution à l'autre avec les mêmes entrées
Cause : Comportement attendu. Le node applique une rotation aléatoire à la liste filtrée et triée avant de retourner le top N, ce qui fait varier la sélection d’une exécution à l’autre.
Solution : Aucune action requise. Augmentez Number of links to return pour obtenir une short-list plus stable, ou normalisez la sortie de façon déterministe en aval.
Bonnes pratiques et pièges à éviter
Adaptez les poids au cas d’usage. Le maillage éditorial favorise le sémantique (0.8 / 0.3). Les pages piliers et hubs de navigation favorisent l’autorité (0.5 / 0.7). Testez les deux configurations sur une requête de référence.
Rafraîchissez le dataset régulièrement. Les recommandations valent ce que vaut l’export. Recrawlez régulièrement pour rendre les nouvelles pages éligibles et éviter que des inrank obsolètes ne biaisent les résultats.
La qualité des titres conditionne le match sémantique. Des titres génériques (Page 1, Sans titre) ne peuvent pas être appariés. Vérifiez que chaque ligne a un titre descriptif avant d’exploiter la sortie.
Comment s’intègre-t-il dans un workflow ?
Internal Link Recommendation se place typiquement entre une source de contenu et une étape de mise en forme, transformant un sujet en liste JSON d’ancres suggérées que les nodes en aval injectent dans le contenu final.
graph LR
Topic[Text Input
<br/>sujet ou brouillon] --> ILR[Internal Link Recommendation]
ILR --> LLM[LLM
<br/>construit les ancres HTML]
LLM --> Output[Docs Writer
<br/>ou Find and Replace]Nodes complémentaires
Transformez le tableau JSON en ancres HTML, texte brut ou liste de liens Markdown prête à coller.
Extrayez des champs spécifiques (par exemple uniquement les URLs) du tableau de recommandations.
Injectez le bloc de liens généré dans un template de contenu via un placeholder.
Fournissez la requête manuellement pour des exécutions ponctuelles ou des tests.