Find and Replace
Le node Find and Replace sert à rechercher et remplacer des caractères spécifiques dans un texte pour donner en sortie un contenu retravaillé.
À quoi sert le node Find and Replace ?
Le node Find and Replace est un outil de traitement de texte essentiel qui permet de rechercher une chaîne de caractères spécifique (texte ou code) et de la remplacer par une autre. Il est particulièrement utile pour nettoyer, corriger ou formater du contenu généré par des modèles d’IA afin de garantir que votre workflow s’exécute correctement sans erreurs de formatage.
Cas d’usage typiques :
- Supprimer les balises Markdown parasites autour du code généré par un LLM (comme les backticks ```).
- Nettoyer des caractères spéciaux ou des espaces indésirables avant d’insérer des données dans une base de données.
- Remplacer des balises HTML spécifiques (par exemple, transformer des
<h2>en<h3>).
Configuration rapide
Suivez ces étapes pour ajouter et configurer le node Find and Replace dans votre workflow :
Ajouter le node au canevas
Ouvrez la bibliothèque de nodes (Node Library), naviguez dans la catégorie Text > Processing, puis glissez-déposez le node Find and Replace sur votre espace de travail.
Connecter les entrées
Reliez le point de connexion d’entrée (à gauche du node) à la sortie du node précédent contenant le texte ou le code à traiter (comme un node LLM, un Input texte ou un Web Scraper).
Paramétrer les remplacements
Ouvrez les paramètres du node. Dans la section Replacements, cliquez sur + Add pour définir le texte à rechercher (Find) et le texte par lequel vous souhaitez le remplacer (Replace with).
Connecter la sortie
Reliez le point de sortie (à droite du node) au node suivant. Définissez le nom de la variable de réception directement dans ce node suivant pour exploiter le texte nettoyé.
Paramètres de configuration
La configuration du node nécessite de définir précisément ce que vous souhaitez cibler et comment vous souhaitez le transformer.
Champs requis
Name string required default: Find And Replace Nom du node — Extrêmement important pour identifier rapidement le rôle de ce node (ex: “Nettoyage balises JSON”) lors de l’exécution et du débogage du workflow.
Description string required default: Search and replace text patterns in content Description du node — Une courte phrase expliquant quel type de remplacement ce node effectue.
Find string required Texte à trouver — La chaîne de caractères exacte ou l’extrait de code que le node doit rechercher dans le texte d’entrée. Une erreur s’affiche si ce champ est vide lors de la création d’une règle.
Champs optionnels
Replace with string default: Vide Texte de remplacement — Le texte qui remplacera la chaîne trouvée. Note : Ce champ peut être laissé vide si votre objectif est de supprimer complètement le texte recherché.
Case sensitive boolean default: false Sensible à la casse — Si activé, le node fera la distinction entre les majuscules et les minuscules lors de sa recherche (ex: “Texte” sera différent de “texte”).
Vous pouvez ajouter plusieurs remplacements successifs sur un seul et même node Find and Replace en cliquant sur le bouton + Add. Cela est très utile pour nettoyer des structures de code complexes (JSON, HTML, PHP) sans avoir à multiplier les nodes.
Que renvoie le node ?
Le node renvoie un texte brut (string) correspondant au contenu initial retravaillé avec les remplacements effectués. Il n’applique aucune modification ni formatage autre que ceux explicitement demandés dans les paramètres.
Comment récupérer l’output ?
Dans Draft & Goal, vous n’avez pas besoin de chercher un nom de variable complexe généré par le système. Pour exploiter le résultat :
- Tirez un lien depuis la sortie du node Find and Replace.
- Connectez-le à l’entrée du node suivant.
- Dans ce node suivant, créez et nommez votre propre variable (par exemple,
texte_nettoye). Le contenu remplacé y sera automatiquement injecté.
Text string Le texte complet après le traitement de toutes vos règles de remplacement séquentiellement.
Exemples d’utilisation
Cas 1 : Suppression des délimiteurs Markdown d’un LLM
Lorsqu’un modèle d’IA génère du code JSON, il inclut souvent des backticks pour la coloration syntaxique, ce qui empêche les extracteurs de données de fonctionner.
Donnée d’entrée (provenant d’un LLM) :
```json
{
"nom_article": "Comment optimiser son SEO en 2024",
"mot_clé": "stratégie SEO",
"nb_mots": 1250,
"score_SEO": 85,
"danger_SEO": "Faible (quelques liens brisés détectés)"
} ```Configuration des remplacements :
- Replacement 1 :
Find= ```json |Replace= (laissé vide) - Replacement 2 :
Find= ``` |Replace= (laissé vide)
Output généré :
{
"nom_article": "Comment optimiser son SEO en 2024",
"mot_clé": "stratégie SEO",
"nb_mots": 1250,
"score_SEO": 85,
"danger_SEO": "Faible (quelques liens brisés détectés)"
}Cas 2 : Modification de la structure HTML
Vous souhaitez dégrader la hiérarchie des titres d’un texte généré avant de l’injecter dans votre CMS.
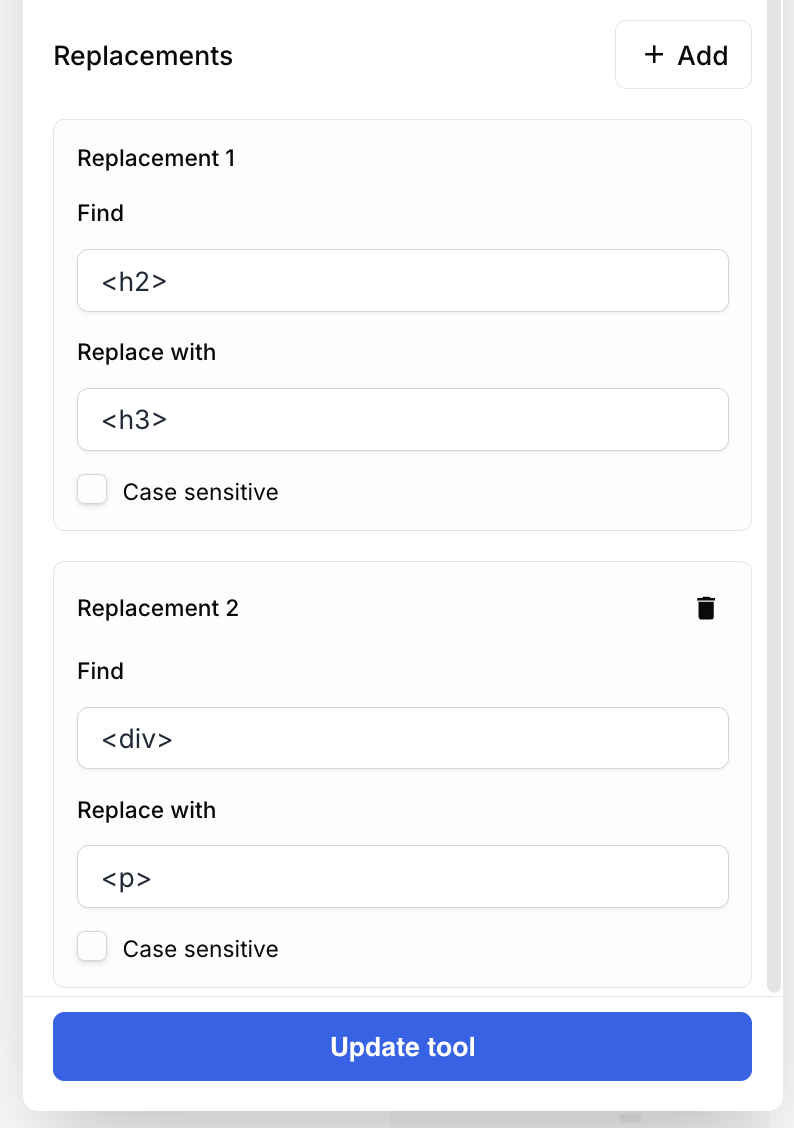
Configuration des remplacements :
- Règle 1 :
Find=<h2>|Replace=<h3> - Règle 2 :
Find=<div>|Replace=<p>
Problèmes courants
Le format de ma page initiale est cassé après le passage du node
Cause : La chaîne de caractères que vous recherchez n’est pas assez précise et a été trouvée à d’autres endroits non désirés dans le texte.
Solution : Soyez extrêmement précis dans le champ Find. Ciblez des chaînes plus longues ou ajoutez des espaces spécifiques pour ne remplacer que l’occurrence souhaitée.
Le node s'est exécuté mais n'a rien remplacé, et je n'ai pas de message d'erreur
Cause : Le texte exact configuré dans le champ Find n’a pas été détecté dans l’entrée. Le node s’exécute silencieusement même s’il ne trouve aucune correspondance.
Solution : Vérifiez que le texte en entrée contient bien la chaîne recherchée. Assurez-vous également que l’option Case sensitive n’est pas activée par erreur si la casse de votre texte d’entrée peut varier.
Bonnes pratiques et pièges à éviter
Dès lors que vous remarquez des erreurs récurrentes dans votre workflow (par exemple, un extracteur qui échoue toujours sur le même caractère d’un output IA), identifiez les mots ou symboles bloquants et insérez un node Find and Replace pour corriger la donnée à la volée.
Attention aux remplacements vides non maîtrisés : Remplacer un simple espace par un champ vide collera tous les mots de votre texte. Testez toujours vos remplacements sur un petit échantillon avant d’exécuter un workflow sur une base de données massive.
Comment s’intègre-t-il dans un workflow ?
Le Find and Replace agit typiquement comme une étape de “nettoyage” ou de “middleware” entre la génération de contenu et son traitement ou son extraction. Voici un schéma typique d’intégration pour l’extraction de données structurées depuis une IA :
graph LR
Input[Input Texte] --> LLM[Node LLM génère JSON]
LLM --> FR[Find and Replace
<br/>nettoie le Markdown]
FR --> Extractor[JSON Path Extractor]
Extractor --> LLM2[Node LLM final]Nodes complémentaires
Générez du texte ou du code, puis utilisez le Find and Replace pour en formater parfaitement la sortie.
Placez ce node juste après un Find and Replace pour extraire de la donnée fiable depuis un JSON préalablement nettoyé.
Une alternative spécialisée si vous souhaitez nettoyer en profondeur des balises HTML complexes.
Convertissez le HTML en Markdown propre avant d’effectuer vos remplacements de caractères spécifiques.