Web Scraper
Le node Web Scraper récupère une page web et en extrait le contenu via des templates intégrés ou des sélecteurs XPath, pour le traitement en aval.
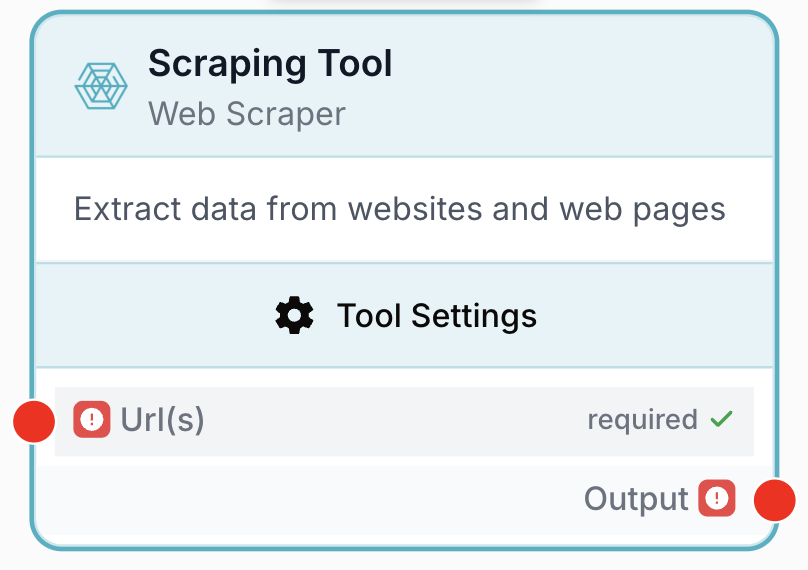
À quoi sert le node Web Scraper ?
Le node Web Scraper récupère une page web depuis une URL et en extrait le contenu. Il peut fonctionner en mode brut (sans template) et renvoyer le contenu de la page sous forme de texte, appliquer l’un des quatre templates intégrés adaptés aux types de pages courants (articles, listes d’articles, produits, listes de produits), ou cibler des éléments précis avec jusqu’à trois sélecteurs XPath. Le node renvoie une chaîne unique que les nodes en aval peuvent nettoyer, parser ou envoyer à un LLM.
Cas d’usage typiques :
- Récupérer le corps d’articles de blog ou de presse avant de les résumer avec un LLM.
- Collecter des fiches produit (nom, prix, description) depuis des listings e-commerce dans un dataset structuré.
- Extraire des éléments précis d’une page connue à l’aide de XPath (prix, notes, champs cachés).
- Itérer sur une liste d’URL dans un Loop pour bâtir un corpus de contenu ou une veille concurrentielle.
Configuration rapide
Suivez ces étapes pour ajouter et configurer le node Web Scraper dans votre workflow :
Ajouter le node au canevas
Ouvrez la bibliothèque de nodes (Node Library), allez dans Integrations, puis glissez-déposez le node Web Scraper sur votre espace de travail.
Connecter ou saisir l’URL
Saisissez directement une URL statique dans l’entrée Url(s), ou reliez la sortie d’un node en amont (Text Input, Loop, JSON Path Extractor) qui fournit l’URL à scraper.
Choisir un template de contenu
Dans les paramètres du node, choisissez un Content Type : conservez No Template pour la page brute, ou sélectionnez Article, ArticleList, Product, ProductList pour appliquer un profil d’extraction prédéfini.
(Optionnel) Ajouter des sélecteurs XPath
Ouvrez la section XPath Selectors et remplissez XPath 1, XPath 2 et/ou XPath 3 pour cibler des nodes DOM précis (ex : //div[@class='product-price']).
Choisir la gestion des erreurs
Sélectionnez une stratégie d’Error Handling : None pour faire échouer le run en cas d’erreur, ou Skip & Continue pour renvoyer une chaîne vide pour cette URL et poursuivre.
Connecter la sortie
Reliez le point de sortie (à droite du node) au node suivant, puis créez et nommez votre propre variable dans ce node suivant pour recevoir le contenu scrapé.
Paramètres de configuration
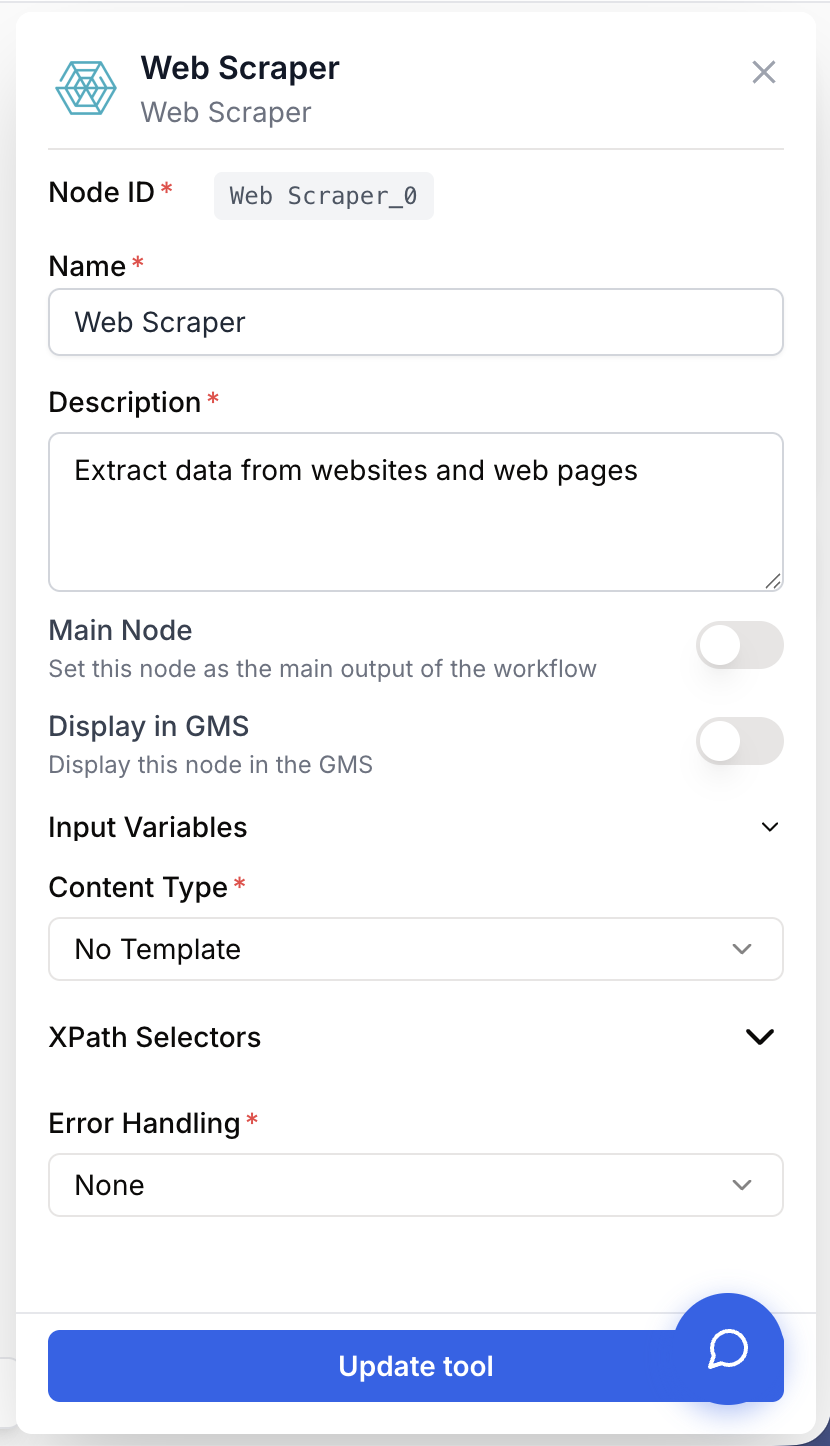
Le Web Scraper expose un point d’entrée et quatre paramètres métier en plus des champs d’identification standard.
Champs requis
Name string required default: Scraping Tool Nom du node — Important pour identifier rapidement le rôle de ce node (ex : Scraping page produit concurrent) lors de l’exécution et du débogage du workflow.
Description string required default: A tool to scrape web content using XPath selectors Description du node — Phrase courte décrivant ce que ce node de scraping récupère dans le contexte de votre workflow.
Url(s) string required URL à scraper — L’URL de la page web à récupérer. Peut être une chaîne en dur ou une variable injectée par un node en amont (Text Input, itération de Loop, JSON Path Extractor, etc.).
Content Type string required default: No Template Template d’extraction — Définit la façon d’extraire la page. Valeurs disponibles :
| Valeur | Comportement |
|---|---|
No Template | Renvoie le contenu brut de la page, sans template. |
Article | Extrait un article unique (titre, corps, métadonnées). |
ArticleList | Extrait une liste d’articles depuis une page d’index. |
Product | Extrait un produit unique (nom, prix, description). |
ProductList | Extrait une liste de produits depuis une page de listing. |
Error Handling string required default: None Stratégie de gestion d’erreur — Contrôle la réaction du node lorsque la page ne peut être récupérée ou parsée :
| Valeur | Comportement |
|---|---|
None | En cas d’erreur, le node s’arrête et le run du workflow échoue. |
Skip & Continue | En cas d’erreur, le node renvoie une chaîne vide pour cette URL et l’exécution continue. |
Champs optionnels
XPath 1 string default: Empty Premier sélecteur XPath — Expression XPath personnalisée pour cibler un élément précis de la page (ex : //div[@class='product-title']). Combinée avec le template choisi lorsque les deux sont renseignés.
XPath 2 string default: Empty Deuxième sélecteur XPath — XPath additionnel, typiquement utilisé pour extraire une seconde information (ex : //div[@class='product-price']).
XPath 3 string default: Empty Troisième sélecteur XPath — XPath additionnel, typiquement utilisé pour extraire une troisième information (ex : //div[@class='product-description']).
Commencez avec No Template et un seul XPath en prototypage, inspectez le résultat brut, puis passez à un template (Article, Product…) seulement une fois que vous savez quels champs vous utilisez réellement en aval.
Que renvoie le node ?
Le node renvoie une chaîne unique nommée html qui contient le contenu scrapé. La forme exacte de cette chaîne dépend du Content Type choisi et des sélecteurs XPath :
- Avec
No Template, la sortie est le contenu brut de la page (généralement du HTML). - Avec un template (
Article,ArticleList,Product,ProductList), la sortie est une représentation textuelle sérialisée des champs extraits. - Avec des sélecteurs XPath, la sortie se concentre sur les nodes DOM correspondants.
Comment utiliser la sortie
Dans Draft & Goal, vous n’avez pas besoin de chercher un nom de variable généré par le système. Pour utiliser le résultat :
- Tirez une connexion depuis la sortie du Web Scraper.
- Reliez-la à l’entrée du node suivant (HTML to Markdown, HTML Cleaner, JSON Path Extractor, LLM, etc.).
- Dans ce node suivant, créez et nommez votre propre variable (par exemple
scraped_page). Le contenu scrapé y sera injecté automatiquement.
html string Le contenu scrapé, renvoyé sous forme de chaîne. Vide lorsque l’URL ne se charge pas et que Error Handling est positionné sur Skip & Continue.
Exemples d’utilisation
Exemple 1 : Scraper un article et le résumer avec un LLM
Vous voulez transformer n’importe quelle URL d’article en un briefing court.
Workflow :
- Text Input contient l’URL de l’article.
- Web Scraper la récupère avec
Content Type = ArticleetError Handling = Skip & Continue. - HTML to Markdown nettoie la sortie pour le LLM.
- LLM reçoit le markdown et produit le résumé.
Configuration du Web Scraper :
Url(s)={{Text_0.value}}Content Type=ArticleError Handling=Skip & Continue
Exemple 2 : Extraction produit ciblée avec XPath
Vous suivez la fiche produit d’un concurrent et n’avez besoin que du titre, du prix et de la description.
Configuration du Web Scraper :
Url(s)=https://shop.example.com/product/123Content Type=ProductXPath 1=//div[@class='product-title']XPath 2=//div[@class='product-price']XPath 3=//div[@class='product-description']Error Handling=None
La sortie html contient alors les trois blocs ciblés, prêts à être parsés par un JSON Path Extractor ou envoyés à un LLM pour normalisation.
Exemple 3 : Scraping en lot avec un Loop
Vous disposez d’une liste d’URL et voulez scraper chacune puis stocker le résultat.
Workflow :
- Create List (ou un API Connector en amont) fournit la liste d’URL.
- Loop itère sur chaque élément.
- Web Scraper scrape l’URL courante avec
Url(s) = {{Loop_0.currentItem}}etError Handling = Skip & Continueafin qu’une page en échec n’interrompe pas le run. - Sauvegarde / ajout du résultat en aval (Sheets, base de données, fichier).
Problèmes courants
La sortie est vide alors que l'URL fonctionne dans mon navigateur
Cause : La page peut afficher son contenu via JavaScript après le chargement, ou bloquer les requêtes automatisées : dans ce cas le HTML brut vu par le scraper ne contient pas le texte attendu.
Solution : Ouvrez le code source de la page (et non le DOM des dev tools) pour vérifier que la donnée est bien présente dans le HTML initial. Si elle est rendue côté client, le Web Scraper ne peut pas l’atteindre. Si la page bloque les scrapers, basculez sur une API officielle ou une autre source.
Un XPath ne renvoie rien
Cause : Le XPath ne correspond pas à la structure réelle du DOM, ou il cible des attributs différents de ce qui est rendu côté serveur.
Solution : Testez d’abord le XPath dans les dev tools du navigateur ($x("//div[@class='product-title']")). Préférez des sélecteurs robustes (contains(@class, 'price')) plutôt que des sélecteurs fragiles dépendant de classes volatiles.
Mon workflow s'arrête à la première mauvaise URL dans un Loop
Cause : Error Handling est positionné sur None, donc la première réponse non-200 ou erreur de parsing arrête le run.
Solution : Passez Error Handling sur Skip & Continue. Le node renvoie une chaîne vide pour l’URL en échec et le Loop continue sur l’élément suivant.
La sortie est difficile à donner à un LLM
Cause : Le HTML brut contient beaucoup de balisage inutile pour le modèle.
Solution : Placez un node HTML Cleaner ou HTML to Markdown entre le Web Scraper et le LLM pour réduire le bruit et la consommation de tokens.
Bonnes pratiques et pièges
Positionnez toujours Error Handling sur Skip & Continue lorsque le Web Scraper est dans un Loop. Une URL inaccessible sur cent ne devrait pas faire échouer le batch entier.
Respectez les sites cibles. Vérifiez les conditions d’utilisation et le robots.txt avant de scraper à grande échelle, espacez vos Loops pour ne pas saturer les serveurs, et préférez les API officielles quand elles existent.
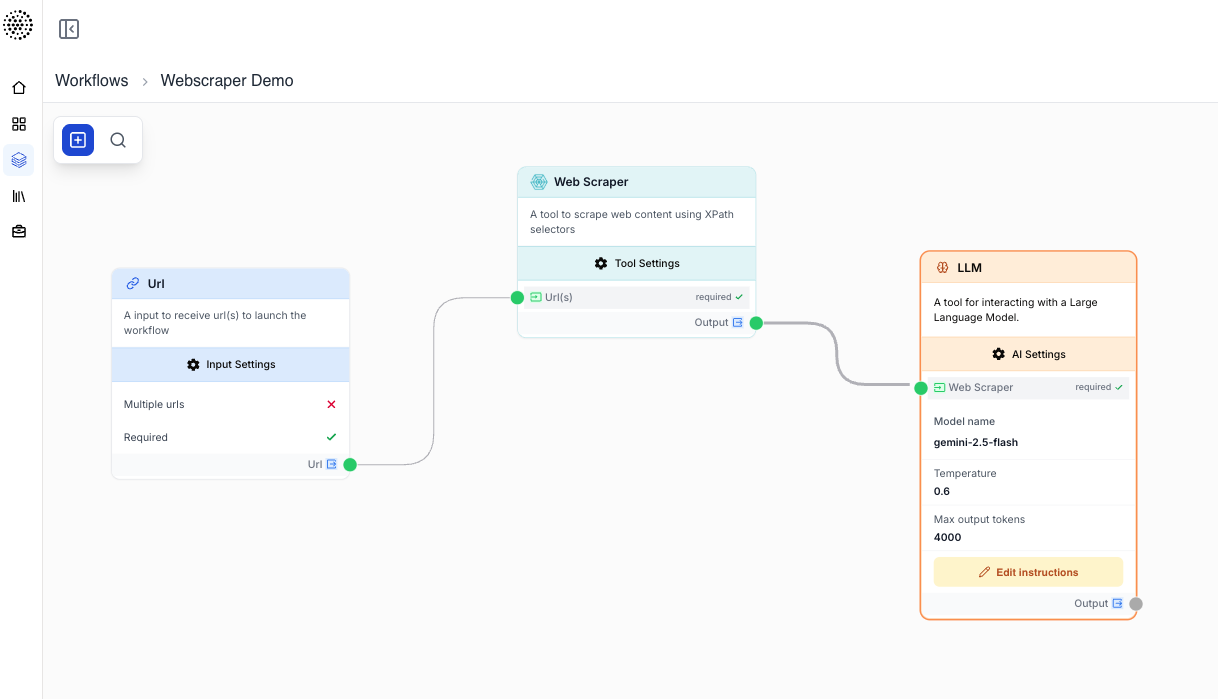
Comment s’intègre-t-il dans un workflow ?
Le Web Scraper se place typiquement entre un node qui produit des URL et un node qui nettoie ou interprète le résultat. Voici un schéma classique de scraping en lot avec nettoyage et analyse LLM :
graph LR
Source[Liste d'URL / API Connector] --> Loop[Loop]
Loop --> Scraper[Web Scraper]
Scraper --> Clean[HTML to Markdown]
Clean --> LLM[Analyse LLM]
LLM --> Out[Sauvegarder résultats]Nodes associés
Supprimer le bruit du HTML scrapé avant de le parser ou de l’envoyer à un LLM.
Convertir le HTML scrapé en Markdown propre, mieux géré par les LLM que le markup brut.
Scraper une liste d’URL une par une, avec Error Handling = Skip & Continue pour ignorer les échecs.
Extraire un champ précis du payload scrapé une fois qu’il a été transformé en JSON.